
《JS 核心原理解析》笔记
这个月读的周爱民老师的一门课, 老实说全是底层, 够难懂的, 后面还得二刷三刷...
引子
JavaScript 是一门多范型语言,也称为混合范型语言, 它既有 OOP 的特性, 也有函数式的特性. JavaScript 的简单来自于此, 复杂也来自于此; 生存能力来自于此, 抨击诟病也来自于此. JavaScript 主要包括 5 个方面的语言特性: 结构化编程, 面向对象编程, 动态语言, 函数式语言和并行语言. JavaScript 中, 有语句和表达式两种基本的可执行元素.
谈一谈 JavaScript 的动态类型和弱类型
在声明变量之前需要先定义变量类型, 我们把这种在使用之前就需要确认其变量数据类型的称为静态语言. 相反地, 我们把在运行过程中需要检查数据类型的语言称为动态语言.
考察这段 Javascript 语句, `if (1)`, 1 实际会被隐式转成 true. 这种支持隐式类型转换的语言称为弱类型语言, 不支持隐式类型转换的语言称为强类型语言.
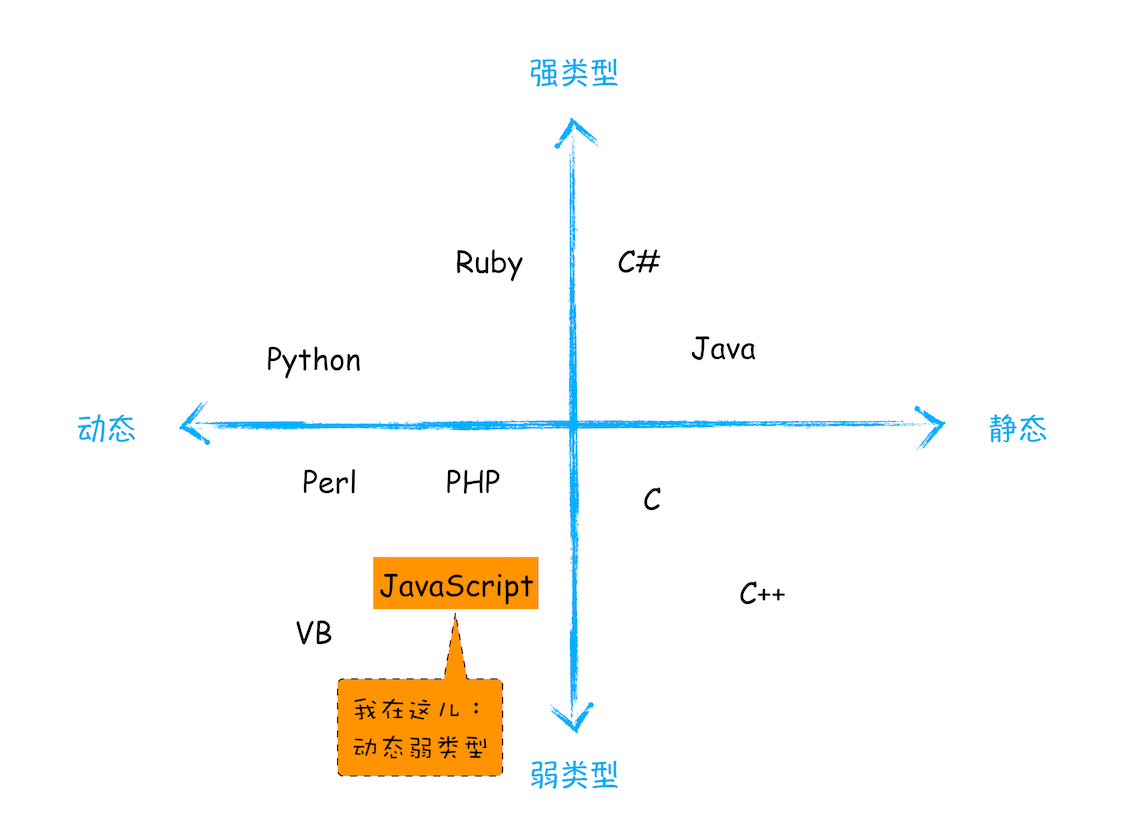
JavaScript 是一种弱类型的, 动态的语言:
- 弱类型, 意味着你不需要告诉 JavaScript 引擎这个或那个变量是什么数据类型, JavaScript 引擎在运行代码的时候自己会计算出来.
- 动态, 意味着你可以使用同一个变量保存不同类型的数据.
谈一谈 delete
我们使用 delete 最多的场景就是删除对象中的某个 key, 这是操作的一个引用类型. 其实仔细想想, `delete 0` 相当于删除一个基本类型, 甚至你还可以删除全局对象的某个 key, 比如在浏览器环境中, 你可以 `delete scrollX`. 因此, `delete x`, x 可以是引用类型, 也可以是基本类型, 也可以是全局对象(当然它也是引用类型).
首先看 `delete 0`, 0 是一个具体的字面量值, 是不可能删除掉的, 但 `delete 0` 仍然会返回 true, 这只表明执行过程中没有异常, 但实际的执行行为是"什么也没发生". 你显然不可能真的将 0 从执行系统中清理出去.
那么接下来, 就还剩下删除变量和删除属性, 由于全局变量实际上是通过全局对象的属性来实现的, 因此删除变量也就存在识别这两种行为的必要性. 出于 JavaScript 是动态语言这项特性, 从根本上来说, 我们是没有办法在语法分析期来判断 x 的性质的, 需要有一种方法在运行期来标识 x 的性质, 以便进一步地处理它.
对于一门编译型语言来说, 0 可以是原始类型 0, 也可以是数值类型 `Number(0)`. 但在编译之前, 也就是语法分析的阶段, 0 仅仅是一个 Token. 一个记号是没有语义的, 记号既可以是语言能识别的, 也可以是语言不能识别的. 唯有把这二者同时纳入语言范畴, 那么这个语言才能识别所谓的"语法错误". 因此, 这个语法实际起作用的是一个对象的属性, 也就是"删除对象的成员". 是删除 x 这个成员, 而不是删除 x 这个值.
表达式的值, 在 ECMAScript 的规范中, 称为引用. 对于 delete 0, 实际上是在说: JavaScript 将 0 视为一个表达式, 并尝试删除它的求值结果.
- 如果它是值, 则按照传统的 JavaScript 的约定返回 true;
- 如果它是一个引用, 那么对该引用进行分析, 以决定如何操作.
ECMAScript 约定: 任何表达式计算的结果(Result)要么是一个值, 要么是一个引用. delete {} 这个对象字面量 , 当它被作为表达式执行的时候, 结果也是一个值.
所有赋值操作的含义, 是将右边的值, 赋给左边用于包含该值的引用. 如果 x 放在左边作为 lhs, 那么它是引用; 如果放在右边作为 rhs, 那么就是值. 所以 `x = x` 的语义并不是x 赋给 x, 而是把值 x 赋给引用 x.
而对于 `obj.x()`, 如果 obj.x 只是值, 或者它作为右手端, 那么它就不能携带 obj 这个对象, 也就完成不了后续的方法调用操作.
所以, delete x归根到底, 是在删除一个表达式的, 引用类型的结果(Result), 而不是在删除 x 表达式, 或者这个删除表达式的值(Value).
- delete 运算符尝试删除值数据时, 会返回 true, 用于表示没有错误(Error).
- delete 0 的本质是删除一个表达式的值(Result).
- delete x 与上述的区别只在于 Result 是一个引用(Reference)
- delete 其实只能删除一种引用, 即对象的成员(Property)
因此, 在 JavaScript 中. 引用类型, 也就是 Obeject, Fuction 这些, 归因于它们存在于堆內存; 而基础类型, 如 Number, String, Boolean, null, undefined, 归因于它们存在于栈内存. 但注意的是引用和引用类型是不同的概念.
最后写几个例子:
let x = 1; delete x; // false delete unexistingVariable; // true const o = {}; Object.defineProperty(o, "name", { value: "yancey", configurable: false, }); delete o.name; // false
谈一谈声明语句
至今为止, 除标签声明之外, JavaScript 中一共只有六条声明用的语句: let, const, var, function, import, class. 此外还有两个不太严格的声明语句, 分别是 `for(var|let|const x ...)` 和 `try...catch`. 比如 `var a = 1`, var a 就是一个声明, 后面是一个赋值运算.
除上述的语法, 用户是没有其它方式来在当前的代码上下文中声明出一个标识符来的, 因为所有的声明都有以下两个特征:
- 意味着 JavaScript 将可以通过静态语法分析发现那些声明的标识符
- 标识符对应的变量 / 常量一定会在用户代码执行前就已经被创建在作用域中.
下面这个例子, 正是由于 var y 所声明的那个标识符在函数 f() 创建(它自己的闭包)时就已经存在, 所以才阻止了 console.log(y)访问全局环境中的 y. 类似的, let x 所声明的那个 x 其实也已经存在 f() 函数的上下文环境中. 访问它之所以会抛出异常(Exception), 不是因为它不存在, 而是因为这个标识符被拒绝访问了(临时死区).
var y = "outer"; function f() { console.log(y); // undefined console.log(x); // throw a Exception let x = 100; var y = 100; }
变量提升
JavaScript 是允许访问还没有绑定值的 var 所声明的标识符的, 这种标识符后来统一约定称为变量声明(VarDelcs); 而 let/const 则称为词法声明(LexicalDecls). JavaScript 环境在创建一个 var 变量名后, 会初始化绑定一个 undefined 值. 而 let/const 则会初始化绑定一个 undefined, 而 let/const 没这个待遇, 它们在缺省情况下就是"还没有绑定值"的标识符, 且 const 必须赋初值.
回到上面六条声明用的语句, 函数是按 varDecls 的规则声明的; 类 1 的内部是严格模式, 名字按 let 处理; import 按照 const 的规则处理. 因此所有的声明本质上只有三种处理模式: var 变量声明, let 变量声明和 const 常量声明.
补充, import 语句会发生变量提升的效果, 这是因为 ESModule 根据 import 构建依赖树, 所以在代码运行前名字就是已经存在于上下文, 然后在运行模块最顶层代码, 给名字绑定值, 就出现了变量提升的效果.
赋值
将右操作数(的值)赋给左操作数(的引用), 一个赋值表达式的左边和右边其实都是表达式.
LeftHandSideExpression < = | AssignmentOperator > AssignmentExpression
向一个不存在的变量赋值
现在的 JavaScript 环境仍然是通过将全局对象初始化为一个全局闭包来实现的. 但是为了得到一个尽可能与其它变量环境相似的声明效果(varDecls), ECMAScript 规定在这个全局对象之外再维护一个变量名列表(varNames), 所有在静态语法分析期或在 eval() 中使用 var 声明的变量名就被放在这个列表中. 然后约定, 这个变量名列表中的变量是"直接声明的变量", 不能使用 delete 删除.
当然 let, const 是不存在这种事情的, 它们不会被挂在 global 下.
// 这两个都挂在了全局对象上, 可以通过 global. 获取 // 不同的是, a 是不可删除的, b 是可删除的 // 是否能够被删除可通过 configurable 属性符来判断 var a = 100; x = 200; Object.getOwnPropertyDescriptor(global, "a"); // { value: 100, writable: true, enumerable: true, configurable: false } Object.getOwnPropertyDescriptor(global, "x"); // { value: 200, writable: true, enumerable: true, configurable: true }
因此回到今天讨论的这行代码 `var x = y = 100`, 在这行代码中, 等号的右边是一个表达式 y = 100, 它发生了一次向不存在的变量赋值, 所以它隐式地声明了一个全局变量 y, 并赋值为 100. x 和 y 是两个不同的东西, 前者是声明的名字, 后者是一个赋值过程可能创建的变量名.
var 关键字所声明的, 事实上有且仅有 x 一个变量名, 变量 y 会因为赋值操作而导致 JavaScript 引擎意外创建一个全局变量, 去除掉`var x` 之后剩下的部分, 并不是一个严格意义上的赋值运算, 而是被称为初始器(Initializer)的语法组件. 因此, x 只是一个表达名字的, 静态语法分析期作为标识符来理解的字面文本, 而不是一个表达式. 而对于 `x = y = 0`, x 是一个表达式了, 它被严格地称为赋值表达式的左手端(lhs)操作数.
Initializer: = AssignmentExpression
关于全局变量有两个规则:
- 向没有声明的变量名赋值, 会隐式地创建一个全局变量;
- 全局变量会被绑定为全局对象(global)的属性.
var a = 1; b = 2; window.a; // 1 window.b; // 2
a.x = a = { n: 2} 经典问题
var a = { n: 1 }, ref = a; a.x = a = { n: 2 }; console.log(a.x); // undefined console.log(ref.x); // { n: 2 }
首先, 对于第一行, 声明一个 a 变量, 赋值为 `{ n: 1 }`. 对于第二行, 因为 js 操作是从左往右, a.x 先执行, 给 a 这个引用里面添加一个 x 属性, x 属性是什么呢? 看等号右边, 为一个赋值表达式(可以把连续赋值看作一个嵌套函数, 等号左边都是引用, 右边都是值, 执行是从前往后, 但赋值是从后往前), 那么要做的就是求赋值表达式的值; 即 `a = { n: 2 }`, 这是第一次赋值, 这时候 a 这个变量的引用已经发生了变化, 指向了另一块地址, 这时候过去的 a 的引用地址就找不到了. 那么对于第三行, 当你再打印 a.x 时, 这里面的 a 其实是新的引用地址, 打印出来自然是 undefined,

谈一谈 export
ECMAScript 6 模块是静态装配的, 而传统的 Node.js 模块却是动态加载的.
// 导出"声明的(名字)" export <let/const/var> x ...; export function x() ... export class x ... export {x, y, z, ...}; // 导出"重命名的(名字)" export { x as y, ...}; export { x as default, ... }; // 导出"其它模块的(名字)" export ... from ...; // 导出"值" export default <expression>
`export default` 虽然简单, 却是对导出名字的非常必要的补充. 这样一来, 用户既可以导出那些有名字的数据, 也可以导出那些没有名字的数据, 即一个模块中所有的数据都可以被导出了.
以 `export var x = 100;` 为例, 在导出的时候. 就是在某个名字表登记上一个名字 x 而已, 这也是 JavaScript 在模块装载之前对 export 所做的全部工作; 而从 import 角度考虑, 比如 `import { x } from 'xxx'`, 它是按照语法在当前模块中声明名字, 添加一个当前模块对目标模块的依赖项. 通过这种方式, JavaScript 就可以依据所有它能在静态文本中发现的 import 语句来形成模块依赖树, 最后就可以找到这个模块依赖树最顶端的根模块, 并尝试加载之.
export 事实上就只能导出名字和值. 然而一旦它能导出名字和值, 也就意味着它能导出一个模块中的全部内容. 在导入导出的过程中, 没有任何一行用户的 JavaScript 代码是被执行过的, 源代码只被理解为静态的, 没有逻辑的代码文本. 这意味着, 在处理 export/import 语句的全程, 没有表达式被执行.
在看下面的例子, 如同 `var x = 100;` 在执行阶段需要有一个将值 100 绑定给变量 x 的过程, export default 也应当有类似的过程来将结果绑定到 default 这个名字上. 在静态装配阶段, 名字 default 只是被初始化为一个单次绑定的, 未初始化的标识符. 因此后续找到并遍历模块依赖树的所有模块, 执行这些模块最顶层的代码. 这意味着, 所谓模块的装配过程, 就是执行一次顶层代码而已.
export var x = 100; export default function() {} export var default = function() {}
对于匿名函数的 export
它并不是导出了一个匿名函数表达式, 而是导出了一个匿名函数定义(Anonymous Function Definition). 下面这个例子, 如果默认导出一个匿名函数, 它会被默认导出到一个名字为 default 的名字空间中.
// b.js export default function () {} // a.js import B from "./b.js"; B.name; // 'default'
如果是个具名函数, 导出后就还会用到这个名字. 其实这种写法在 React 的函数组件中是很常见的做法.
// b.js export default function b() {} // a.js import B from "./b.js"; B.name; // 'b'
其他
`export var x = ''`就意味着在当前模块环境中创建的是一个变量, 并可以修改等等. 但是当它被导入时, 在 import 语句所在的模块中却是一个常量, 因此总是不可写的- 由于
`export default`没有显式地约定名字 default 应该按 let/const/var 的哪一种来创建, 因此 JavaScript 缺省将它创建成一个普通的变量(var), 但即使是在当前模块环境中, 它事实上也是不可写的, 因为你无法访问一个命名为"default"的变量, 因此它是一个关键字. - 所谓匿名函数, 仅仅是当它直接作为操作数时, 才是真正匿名的, 如
`function(){}.name; // ''`. - 由于类表达式, 在本质上就是函数, 它的表现形式和上述一致(参考 React 类组件).
- 导出项(的名字)总是作为词法声明被声明在当前模块作用域中的, 这意味着它不可删除, 且不可重复导出.
- 对于 export 来说是模块的导出表, 对于 import 来说就是名字空间, 如果用户代码不使用
`import * as ...`的语法来创建这个名字空间, 那么该名字表就只存在于 JavaScript 的词法分析过程中, 而不会(或并不必要)创建它在运行期的实例
一个偏门的概念 - for 循环的代价
先复习一下, 在 ECMAScript 6 之后, JavaScript 实现了块级作用域. 然而, 绝大多数 JavaScript 语句都并没有自己的块级作用域. 从语言设计的原则上来看, 越少作用域的执行环境调度效率也就越高, 执行时的性能也就越好. 像 switch, try...catch 是块级作用域, 而 if, for, while 等都不是块级作用域.
在 JavaScript 的具体执行过程中, 作用域是被作为环境的上下文来创建的. 如果将 for 语句的块级作用域称为 forEnv, 并将上述为循环体增加的作用域称为 loopEnv, 那么 loopEnv 它的外部环境就指向 forEnv. 于是在 loopEnv 看来, 变量 i 其实是登记在父级作用域 forEnv 中, 并且 loopEnv 只能使用它作为名字 i 的一个引用. 更准确地说, 在 loopEnv 中访问变量 i, 在本质上就是通过环境链回溯来查找标识符(Resolve identifier, or Get Identifier Reference).
下面这个例子创建了一些定时器. 当定时器被触发时, 函数会通过它的闭包(这些闭包处于 loopEnv 的子级环境中)来回溯, 并试图再次找到那个标识符 i. 然而, 当定时器触发时, 整个 for 迭代有可能都已经结束了. 这其实就是几百年前那个经典的面试题 —— for 循环为 var 遇上 setTimeout 的问题. ES6 之前的解法是通过闭包, 当然之后换成 let 即可, 但换成 let 其实是会有代价的.
因为要想使用 let 的方式符合预期, 这个 loopEnv 就必须是随每次迭代变化的. 也就是说, 需要为每次迭代都创建一个新的作用域副本, 这称为迭代环境(iterationEnv), 因此, 每次迭代在实际上都并不是运行在 loopEnv 中, 而是运行在该次迭代自有的 iterationEnv 中. 也就是说, 在语法上这里只需要两个块级作用域, 而实际运行时却需要为其中的第二个块级作用域创建无数个副本. 这就是 for 语句中使用 let/const 这种块级作用域声明所需要付出的代价. 这个循环体越大, 支持的层次越多, 那么这个环境的创建也就越频繁, 代价越高昂. 再加上可以使用函数闭包将环境传递出去, 或交给别的上下文引用, 这里的负担就更是雪上加霜了. 有个说法是循环与函数递归在语义上等价, 其实不然, 像上面这种, 循环带来的代价并不小.
换句话说, 绝大多数语句并没有块级作用域, 因为它们不需要. 而需要块级作用域的 for 语句, 根本的需求是需要处理多次迭代中的变量暂存, 这个是有很大开销的.
for (let i in [1, 2, 3]) { setTimeout(() => console.log(i), 1000); }
对于一门编译型语言来说, 0 可以是原始类型 0, 也可以是数值类型 `Number(0)`. 但在编译之前, 也就是语法分析的阶段, 0 仅仅是一个 Token. 一个记号是没有语义的, 记号既可以是语言能识别的, 也可以是语言不能识别的. 唯有把这二者同时纳入语言范畴, 那么这个语言才能识别所谓的"语法错误". 因此, 这个语法实际起作用的是一个对象的属性, 也就是"删除对象的成员". 是删除 x 这个成员, 而不是删除 x 这个值. 不过终归有一点是没错的: 既然没办法表达异常, 而 delete 0 又不产生异常, 那么它自然就该返回 true. 所以, delete 这个操作的正式语法设计并不是"删除某个东西", 而是"删除一个表达式的结果".
谈一谈 break
所谓可中断语句其实只有两种, 包括全部的循环语句, 以及 switch 语句. 在这两种语句内部使用的 break, 采用的就是这种处理机制, 即中断当前语句, 将执行逻辑交给下一语句. 第二种还有标签语句, JavaScript 和 Rust 都有该语法. 当然除了 break, 也可以是 continue.
// 在 if 语句的两个分支中都可以使用 break // 在分支中深层嵌套的语句中也是可以使用 break 的 aaa: if (true) { ... } else { ... break aaa; } // 在 try...catch...finally 中也可以使用 break bbb: try { ... } finally { break bbb; }
在重学前端的课程学到了即便在 try 中 return 了, 还是会执行 finally 里面的代码, 这涉及 JavaScript 语句执行的完成状态(Completion Record), 如果在 try 或 try..finally 块中使用了 return, 那么这个 break 将发生于最后一行语句之后, 但是却是在 return 语句之前. 下面的代码会依次打印出 Hi, Here, 101. 换句话说, 虽然 try 里面有 return, 但到了 finally 语句的时候, 把 try 里面给 break 掉了, 这得以继续执行下面的语句. 因此, break 将语句的代码块理解为位置, 而不是理解为作用域 / 环境.
var i = 100; function foo() { bbb: try { console.log("Hi"); return i++; // <- 位置 1: i++ 表达式将被执行 } finally { break bbb; } console.log("Here"); return i; // <- 位置 2 } function f() { try { return 1; } finally { console.log("finally"); } console.log("a"); // 执行不到了 }
JavaScript 的执行机制包括执行权和数据资源两个部分, 分别映射可计算系统中的逻辑与数据. 而块级作用域(也称为词法作用域)以及其他的作用域本质上就是一帧数据, 以保存执行现场的一个瞬时状态(也就是每一个执行步骤后的现场快照). 而 JavaScript 的运行环境被描述为一个后入先出的栈, 这个栈顶永远就是当前执行权的所有者持用的那一帧数据, 也就是代码活动的现场.
- 块级作用域以及其他的作用域本质上就是一帧数据, 交由所谓环境来管理;
- 函数是通过 CALL/RETURN 来模拟上述数据帧在栈上的入栈与出栈过程, 也称为调用栈;
- 执行现场是上述环境和调用栈的一个瞬时快照(包括栈上数据的状态和执行的位置).
所以, 作用域就是在上述过程中被操作的一个对象.
- 作用域退出, 就是函数 RETURN.
- 作用域挂起, 就是执行权的转移.
- 作用域的创建, 就是一个闭包的初始化.
- ...
而 `break labelName` 这一语法独立于执行过程 的体系, 它表达一个位置的跳转, 而不是一个数据帧在栈上的进出栈. 这是 labelName 独立于标识符体系(也就是词法环境)所带来的附加收益. 当然 JavaScript 用来抹平这种跳转所带来的影响, 需要额外的设计.
语句执行的完成状态(Completion Record)
语句执行与函数执行并不一样. 函数是求值, 所以返回的是对该函数求值的结果(Result), 该结果或是值(Value), 或是结果的引用(Reference). 而语句是命令, 语句执行的返回结果是该命令得以完成的状态(Completion, Completion Record Specification Type). 语句执行总是返回它的完成状态.
在 ECMAScript 规范层面, 本质上所有 JavaScript 的执行都是语句执行(这很大程度上解释了为什么 eval 是执行语句). 因此, ECMAScript 规范中对执行的描述都称为运行期语义(Runtime Semantics), 它描述一个 JavaScript 内部的行为或者用户逻辑的行为的过程与结果. 也就是说这些运行期语义都最终会以一个完成状态(Completion)来返回. 例如:
- 一个函数的调用: 调用函数——执行函数体(EvaluateBody)并得到它的完成结果(result).
- 一个块语句的执行: 执行块中的每行语句, 得到它们的完成结果(result).
这些结果(result)包括的状态有五种, 称为完成的类型:
- 正常完成(normal)
- 一个函数调用的返回(return)
- 循环过程中的继续下次迭代(continue)
- 中断(break)
- 异常(throw)
所以当运行期出现了一这个称为中断(break)的状态时, JavaScript 引擎需要找到这个break标示的目标位置(result.Target), 然后与当前语句的标签(如果有的话)对比:
- 如果一样, 则取 break 源位置的语句执行结果为值(Value)并以正常完成状态返回;
- 如果不一样, 则继续返回 break 状态.
在这个示例中, break aaa语句是发生于 bbb 标签所示块中的. 但当这个中断发生时:
- 标签化语句 bbb 将首先捕获到这个语句完成状态, 并携带有标签 aaa
- 由于 bbb 语句完成时检查到的状态中的中断目标(Target)与自己的标签不同, 所以它将这个状态继续作为自己的完成状态, 返回给外层的 aaa 标签化语句 aaa;
- 语句 aaa 得到上述状态, 并对比标签成功, 返回结果为语句
`3 + 4`的值(作为完成状态传出).
console.log( eval(` aaa: { 1 + 2; bbb: { 3 + 4; break aaa; } } `) ); // 输出值: 7
下面是一些有用的结论, 任何被 break 的代码上下文中, 最后执行语句必然会是break 语句本身. break 语句不返回任何值(ECMAScript 内部约定用Empty值来表示); 不返回任何值的语句, 也不会影响任何语句的既有返回值. break 语句返回值的两个关键特性的由来: 它的类型必然是break; 它的返回值必然是空(Empty). 无论如何, 语句总是一个树或子树(除了空语句可以做叶子结点), 而表达式可以是一个子树或一个叶子结点.
谈一谈 JavaScript 中的模版
模板, 其实就是一种特殊的可执行结构. 所有特殊可执行结构其实都是来自于某种固定的, 确定的逻辑. 这些逻辑语义是非常明确的, 输入输出都很确定, 这样才能被设计成一个标准的, 易于理解的可执行结构. 模版, 是一种特殊的可执行结构. 模板字面量是所有可执行结构的集大成者. 它本身是一个特殊的可执行结构, 但是它调动了包括引用, 求值, 标识符绑定, 内部可执行结构存储, 以及执行函数调用在内的全部能力. 下面列举 JavaScript 中语言及语法层面定义的特殊可执行结构.
参数表
在 JavaScript 语言的内核中, 参数表其实是一个独立的语法组件, 用于描述函数传参过程, 说白了就是把参数放在 arguments 列表中, 然后让 arguments 中的值与参数表中的名字对应起来. 下面是一些有用的概念.
- 对于函数来说, 参数表就是在函数调用时传入的参数 0 到 n;
- 对于构造器以及构造器的 new 运算来说, 参数表就是 new 运算的一个运算数;
- 既然提到了 arguments, 那么箭头函数是没有的, 也就意味着箭头函数没有参数表;
- 简单参数(Simple Parameter List), 就是可以在形式参数表中可以明确数出参数个数的, 没有使用扩展风格声明参数的参数表;
- 非简单的参数列表(Non-Simple Parameter List)也好理解, 像默认参数, 剩余参数等.
// 代理和反射中的 argArray 就是参数表 handler.apply = function (target, thisArgument, argArray) {};
扩展风格的参数表
稍微扩展一下默认参数, 剩余参数. 下面这个例子, 在语法分析期, JavaScript 就得帮助该参数登记下 100 这个值. 然后在实际处理这个参数时, 至少需要一个赋值表达式的操作, 用来将这个值与它的名字绑定起来. 所以, foo() 函数调用时, 总有一段执行逻辑来访问形式参数表以及执行这个赋值表达式.
function foo(x = 100) {}
下面这个例子, 由于表达式可以引用上下文中的其它变量, 因此上面的所谓登记, 就不能只是记下一个字面量值那么简单, 必须登记一个表达式, 并且在运行时执行它.
var x = 0; function foo(i = x++) { console.log(i); } foo(); // 0 foo(); // 1
而剩余参数出现之前, 类似的替代方法只有 `Function.apply`. 而参数展开是通过生成器是实现的.
foo(...args); foo.apply(args);
TIPS: 函数参数不允许出现重名参数的原因. 使用传统的简单参数时, 只需要将调用该参数时传入的实际参数与参数对象(arguments)绑定就可以了; 而使用非简单参数时, 需要通过初始器赋值来完成名字与值的绑定, 通常将实际参数与参数对象绑定时, 只需要映射两个数组的下标即可, 而初始器赋值**需要通过名字来索引值以实现绑定, 因此一旦出现重名参数就无法处理了.
赋值模版
模板赋值是 ECMAScript 6 之后提供一种声明标识符的语法, 该语法依赖一个简单的赋值过程, 等号的左侧称为赋值模板(AssignmentPattern), 而右侧称为值(Value). 在 JavaScript 中, 任何出现类似语法或语义过程的位置, 本质上都可以使用模板赋值的. 也就是说, 即使没有这个赋值符号(等号), 只要语义是**向左操作数(lhs)上的标识符, 赋以右操作数(rhs)的值, 那么它就适用于模板赋值.
a = b;
下面这个例子, foo 函数传入一个对象, 且对象的 key 为 x 和 y, 在调用的时候, 它会严格匹配传入的对象的 key 是否与赋值模版的 key 对应. 即向参数表中的形式参数(的名字), 赋以实际参数的值.
function foo({ x, y }) { console.log(x, y); // 1 2 } foo({ x: 1, z: 3, y: 2 });
所有这些地方的赋值模板, 都是在语法解析期就被分析出来, 并在 JavaScript 内部作为一个可执行结构存放着. 然后在运行期, 会用它们来完成一个从右操作数按模板取值, 并赋值给左操作数的过程, 简言之叫做名字和值的绑定. 当然, 对于上面匹配到的值, 我们还得使用这个名字以便进行更多的运算, 那么这个找到名字并使用名字的过程称为发现(Resolve binding), 其结果称为引用(reference). 而引用不是简单的一个语法标识符, 也可以是一个可执行结构, 比如 `"use strict"` 这个指令, 因为它是引用, 也是可执行结构, 对待它, JavaScript 只需要像调用函数一样, 将它处理成一段确定逻辑就可以了.
如 `obj.foo`, 它被称为属性引用(Property Reference). 属性引用不是简单的标识符引用, 而是一个属性存取运算的结果. 它是为数不多的, 可以存储原表达式信息, 并将该信息传递到后续表达式的特殊结构. 这与 JavaScript 中的方法调用这一语义的特殊实现有关, JavaScript 并不是静态分析的, 因此它无法在语法阶段确定 `obj.foo` 是不是一个函数, 也不知道用户代码在得到 `obj.foo` 这个属性之后要拿来做什么用. 直到 `obj.foo()`, JavaScript 引擎才会意识到这里要调用一个方法. 方法调用的时候是需要将 obj 作为 foo() 函数的 this 值传入, 这个信息只能在上一步的属性存取 obj.foo 中才能得到. 所以 obj.foo 作为一个属性引用, 就有责任将这个信息保留下来, 传递给它的下一个运算. 只有这样, 才能完成一次将函数作为对象方法调用的过程. 与参数表和赋值模板有相似的地方, 模板字面量也是将它的形式规格(Formal)作为可执行结构来保存的.
模版调用
模板字面量调用(TemplateLiteral Call)是唯一一个会使用模板字面量的引用形态(并且也没有直接引用它的内部结构)的操作. 这种引用形态的模板字面量也被称为标签模板(Tagged Templates), 主要包括模板的位置和那些可计算的标签的信息. 模板字面量的内部结构中, 主要包括将模板多段截开的一个数组, 原始的模板文本(raw)等等. 在引擎处理模板时, 只会将该模板解析一次, 并将这些信息作为一个可执行结构缓存起来(以避免多次解析降低性能).
var x = 1; foo = (...args) => console.log(...args); foo`${x}`; // [ '', '', { raw: ['', ''] } ] 1
函数的执行过程
语句执行是命令式范型的体现, 而函数执行代表了 JavaScript 中对函数式范型的理解. 从静态视角来观察, 它就是一个函数对象(Fuction 的实例), 再深入一点函数就是具有 `[[Call]]` 私有属性的对象. 如果不考虑它作为对象的那些特性, 那么函数也无非就是如下三个语义组件组成的(三者缺一不可):
- 参数: 函数总是有参数的, 即使它的形式参数表为空;
- 执行体: 函数总是有它的执行过程, 即使是空的函数体或空语句;
- 结果: 函数总是有它的执行的结果, 即使是 undefined.
JavaScript 的函数是非惰性求值的, 也就是说在函数界面上不会传入一个延迟计算的求值过程, 而是积极地传入已经求值的结果. 在下面这个示例中, 传入函数 f() 的将是赋值表达式 `a = 100` 完成计算求值之后的结果. 考虑到这个结果总是存在值和引用两种表达形式, 所以 JavaScript 在这里约定传值. 于是, 上述示例代码最终执行到的将是 `f(100)`. 而 `a = 100` 这行表达式执行在函数外上下文环境中, 例子中是全局环境.
// 一般函数声明 function f(x) { console.log(x); // 100 } // 表达式 a = 100 是非惰性求值的 f((a = 100));
接下来才来到具体调用这个函数 f()的步骤中. 而直到这个时候, JavaScript 才需要向环境中的那些名字(例如 function f(x)中的形式参数名 x), 绑定实际传入的值. 对于这个 x 来说, 由于参数与函数体使用同一个块作用域, 因此如果函数参数与函数内变量同名, 那么它们事实上将是同一个变量. 函数内的三个 x 实际将是同一个变量, 因此这里的 `console.log(x)`将显示变量 x 的传入参数值 100, 而 `var x = 200;` 并不会导致重新声明一个变量, 仅仅是覆盖了既有的 x.
function f(x) { console.log(x); // 100 var x = 200; console.log(x); // 200 } // 由于非惰性求值, 所以下面的代码在函数调用上完全等义于上例中 f(a = 100) f(100);
因此, 参数的登记过程发生在闭包创建的过程中, 也就是说传入参数的过程执行于函数之外, 比如 `f((a = 100))`, `a = 100` 这个语句是在函数外执行的, 而绑定参数的过程执行于函数内.
迭代的过程
// 迭代函数 function foo(x = 5) { return { next: () => { return { done: !x, value: x && x-- }; }, }; } let x = new Object(); x[Symbol.iterator] = foo; // default `x` is 5 console.log(...x); // 5 4 3 2 1
连续的 tor.next() 调用最终仅是为了获取它们的值 `result.value`, 那么如果封装这些值的生成过程, 就可以用一个新的函数来替代一批函数. 这样的一个函数就称为生成器函数. 由于函数只有一个出口, 所以用函数的退出是无法映射函数包含一个多次生成值的过程这样的概念的. 如果要实现这一点, 就必须让函数可以多次进入和退出, 或者说通过挂起, 保证函数不会报销毁. 同时, 它在挂起当前函数时, 还将函数所在栈上的执行现场移出了调用栈.
- 逻辑上: 它产生一次函数的退出, 并接受下一次 tor.next() 调用所需要的进入;
- 数据上: 它在退出时传出指定的值(结果), 并在进入时携带传入的数据(参数).
function* foo(x = 5) { while (x--) yield x; } // 测试 let x = Object.create(null); x[Symbol.iterator] = foo; // default `x` is 5 console.log(...x); // 4 3 2 1 0
环境和上下文
环境是 JavaScript 在语言系统中的静态组件, 而上下文是它在执行系统中的动态组件.
环境
JavaScript 中, 环境可以细分为四种, 并由两个类别的基础环境组件构成. 这四种环境是: 全局(Global), 函数(Function), 模块(Module)和 Eval 环境; 两个基础组件的类别分别是: 声明环境(Declarative Environment)和对象环境(Object Environment).
这些环境有分为两种类别:
- 声明环境就是名字表, 可以是引擎内核用任何方式来实现的一个名字 -> 数据的对照表;
- 对象环境是 JavaScript 的一个对象, 用来模拟 / 映射成上述的对照表的一个结果.
因此, 所有的环境本质上只有一个功能, 就是用来管理名字 -> 数据的对照表; 对象环境只为全局环境的 global 对象, 或 `with (obj)` 语句中的对象 obj 创建, 其他情况下创建的环境, 都必然是声明环境.
而对于 var, 会发生变量提升, 也就是在一个变量赋值前就能访问它. 因此, 自 ECMAScript 5 开始约定, ECMAScript 的执行上下文将有两个环境, 一个称为词法环境(Lexical Environment), 另一个就称为变量环境(Variable Environment), 所有传统风格的 var 声明和函数声明通过变量环境来管理. 而在内核上, 全局上下文的词法环境和变量环境指向是一样的. 也就意味着词法变量和 var 变量共用一个名字表, 因此你声明了 var 变量, 那么就不能声明同名的 let/const 变量.
var x = 100; let x = 200; // SyntaxError: Identifier 'x' has already been declared
执行上下文
上下文指的是一个外部的, 内部的或由全局 / 模块入口映射成的函数. JavaScript 的执行系统由一个执行栈和一个执行队列构成. 在执行队列中保存的是待执行的任务, 称为 Job. 每一个执行上下文都需要关联到一个对照表. 这个对照表, 就称为词法环境(Lexical Environment).
模块入口是所有模块的顶层代码的顺序组合, 它们被封装为一个称为顶层模块执行(TopLevelModule Evaluation Job)的函数中来作为模块加载的第一个执行上下文创建. 一般 .js 文件也会创建一个脚本执行(Script Evaluation Job) 的函数, 这也是文件加载中所有全局代码块被称为 script 块的原因. eval 也是会开启一个执行上下文, JavaScript 为 eval() 所分配的这个执行上下文, 与调用 eval() 时的函数上下文享有同一个环境(包括词法环境和变量环境等等), 并在退出 eval() 时释放它的引用, 以确保同一个环境中同时只有一个逻辑在执行.
对于普通函数被调用, 它也会形成执行上下文, 但它是被调用的, 所以它会创建一个 caller(调用者), 由于栈是先入后出的, 因此总是立即执行这个 callee 函数的上下文. 因此所有其他上下文都在执行栈上, 而生成器的上下文(多数时间是)在栈的外面.
.next()
对于下面的代码, `let tor = foo3();` 看似执行了一次 foo3, 但实际上, 只要你没有调用 `.next()`, 生成器函数体就是没被执行的. 换言之, 生成一个迭代过程, 并将该过程交给了 tor 对象. 因为 tor 是 foo3() 生成器内部迭代过程的一个句柄. 从引擎内的实现过程来说, tor 其实包括状态(state)和执行上下文(context)两个信息, 它是 GeneratorFunction.prototype 的一个实例. 这个 tor 所代表的生成器在创建出来的时候将立即被挂起, 因此状态值(state)初始化置为"启动时挂起(suspendedStart)", 而当在调用 tor.next() 因 yield 运算而导致的挂起称为 Yield 时挂起(suspendedYield).
function* foo3() { yield 10; } let tor = foo3();
当 tor.next() 执行时, tor 所包括的 context 信息被压到栈顶执行, 当 tor.next() 退出时, 这个 context 就被从栈上移除.
扩展: yield
function* g1() { yield 2; yield 3; yield 4; } function* g2() { yield 1; yield* g1(); yield 5; } var iterator = g2(); console.log(iterator.next()); // { value: 1, done: false } console.log(iterator.next()); // { value: 2, done: false } console.log(iterator.next()); // { value: 3, done: false } console.log(iterator.next()); // { value: 4, done: false } console.log(iterator.next()); // { value: 5, done: false } console.log(iterator.next()); // { value: undefined, done: true }
关于 JavaScript OOP 的漫谈
在 ES6 后, JavaScript 内部是明确区分方法与函数的, 即不能对方法做 new 运算, 否则 JavaScript 会报出 is not a constructor 的异常.
const o = { foo() {}, bar: class A {}, }; new o.foo(); // Uncaught TypeError: o.foo is not a constructor new o.bar(); // 👌
在 ECMAScript 6 之后, 函数可以简单地分为三个大类:
- 类: 只可以做 new 运算;
- 方法: 只可以做调用运算;
- 一般函数: (除部分函数有特殊限制外, 如箭头函数, 生成器函数不能做构造函数), 同时可以做 new 和调用运算.
对于方法:
- 具有一个名为主对象
`[[HomeObject]]`的内部槽; - 没有名为构造器
`[[Construct]]`的内部槽; - 没有名为 prototype 的属性.
ES5 构造函数与 ES6 Class 的区别
Class 类中不存在变量提升.
// ES5 var bar = new Bar(); // 可行 function Bar() { this.bar = 42; } //ES6 const foo = new Foo(); // Uncaught ReferenceError class Foo { constructor() { this.foo = 42; } }
Class 内部会启用严格模式
// ES5 function Bar() { baz = 23; // ok } var bar = new Bar(); // ES6 class Foo { constructor() { this.foo = 42; foo = 12; // Uncaught ReferenceError: foo is not defined } }
Class 内部不能重写类名(修改类名)
// ES5 function Bar() { Bar = "Baz"; this.bar = 42; } var bar = new Bar(); console.log(bar); // Bar {bar: 42} console.log(Bar); // 'Baz' // ES6 class Foo { constructor() { this.foo = 42; Foo = "Fol"; // Uncaught TypeError: Assignment to constant variable. } } let foo = new Foo(); Foo = "Fol"; // it's ok
Class 必须使用 new 调用, 不能直接当函数调用.
// ES5 function Bar() {} var bar = Bar(); // it's ok; // ES6 class Foo {} let foo = Foo(); // Uncaught TypeError: Class constructor Foo cannot be invoked without 'new'
Class 中的所有方法不可枚举
// ES5 function Bar() {} Bar.getName = function () {}; Bar.prototype.say = function () {}; console.log(Object.keys(Bar)); // ["getName"] console.log(Object.keys(Bar.prototype)); // ["say"] // ES6 class Foo { constructor() {} static answer() {} print() {} } console.log(Object.keys(Foo)); // [] console.log(Object.keys(Foo.prototype)); // []
Class 的继承有两条继承链
一条是: 子类的 `__proto__` 指向父类; 另一条是: 子类的 prototype 属性的 `__proto__` 指向父类的 prototype 属性; ES6 子类通过 `__proto__` 属性找到父类, 而 ES5 子类通过 `__proto__` 找到 `Function.prototype`.
// ES5 function Father() {} function Child() {} Child.prototype = new Father(); Child.prototype.constructor = Child; console.log(Child.__proto__ === Function.prototype); // true // ES6 class Father {} class Child extends Father {} console.log(Child.__proto__ === Father); // true
ES5 与 ES6 子类 this 的生成顺序不同
ES5 继承是先建立子类实例对象 this, 再调用父类构造函数修饰子类实例; ES6 继承是先建立父类实例对象 this, 再调用子类构造函数修饰 this. 即在子类构造函数中先调用 super() 方法, 之后再能使用 this. 因此所有 ES5 不能继承原生的构造函数, 而 ES6 可以继承. 此外, 既然 this 是祖先类创建的, 也就意味着在刚刚进入构造方法时, this 引用其实是没有值的, 因此必须采用继承父类的行为的技术, 让父类以及祖先类先把 this 构造出来才行.
浅谈 super
实现 super 这个关键字的核心, 在于为每一个方法添加一个它所属的类这样的性质, 这个性质被称为主对象 (HomeObject).
- 在类声明中, 如果是类静态声明, 也就是使用 static 声明的方法, 那么主对象就是这个类.
- 对于一般声明, 那么该方法的主对象就是该类所使用的原型, 也就是 AClass.prototype.
- 第三种情况, 如果是对象声明, 那么方法的主对象就是对象本身.
super.xxx 在语言内核上是一个规范类型中的引用, 它被标记成 Super Reference, 并且为这个引用专门添加了一个 thisValue 域, ECMAScript 约定了优先取 Super 引用中的 thisValue 值, 然后再取函数上下文中的. 这个 thisValue 是在执行引擎发现 super 这个标识符(GetIdentifierReference)的时候, 就从当前环境中取出来并绑定给 super 引用的. 因此:
- super 关键字所代表的父类对象, 是通过当前方法的
`[[HomeObject]]`的原型链来查找的; - this 引用是从当前环境所绑定的 this 中抄写过来, 并绑定给 super 的.
class Parent { constructor(id) { // <- [[HomeObject]]指向MyClass.prototype} this.id = id; } say() { console.log(this); } } class Child extends Parent { constructor() { super("1"); } bark() { super.say(); // this 指向的是 Child console.log("bark"); } }
关于 constructor, 如果你在 class 中没声明 constructor, 引擎会帮你插进去.
// 如果在class声明中有extends XXX class MyClass extends XXX { // 自动插入的缺省构造方法 constructor(...args) { super(...args); } } // 如果在class声明中没有声明extends class MyClass { // 自动插入的缺省构造方法 constructor() {} }
谈一谈 JavaScript 的对象
JavaScript 中的对象, 在本质上就是关联数组(Associative array, 对应于不可索引的块). 数组在本质上就是索引数组(Index array, 对应于可索引的块).
undefined 用于表达一个值/数据不存在, 也就是非值(non-value), 例如 return 没有返回值, 或变量声明了但没有绑定数据. null 用于表达一个对象不存在, 也就是非对象, 例如在原型继承中上溯原型链直到根类, 根类没有父类, 因此它的原型就指向 null.
没有属性表的对象称为 null. 而一个原子级别的对象, 意味着它只有一个属性表, 它不继承自任何其他既有的对象, 因此这个属性表的原型也就指向 null. 原子对象是对象的最原始的形态. 它的唯一特点就是原型为 null.
任何一个对象 x 都可以通过 `Object.setPrototype(x, null)` 语法变成原子对象, 它可以被理解为关联数组; 并且, 如果它有一个称为 `length` 的属性, 那么它就可以被理解为索引数组.
隐式类型转换(拆箱)
如果一个运算无法确定类型, 那么在类型转换前, 它的运算数将被预设为 number. 预设类型在 ECMAScript 称为 PreferredType. 比如下面的 `[] + {}`, 加号无法判别两个操作数的预期类型, 因此将被预设为 number. 而被预设为 number 的直接后果是优先调用 valueOf, 如果调用了 valueOf 还是对象的话, 那么就会再去调用 toString. 当然如果能够被预设为 string 的话, 那么就直接调用 toString 即可.
`[]` 拆箱的话会先执行 `[].valueOf()`, 得到的是 `[]`, 并不是原始值, 就执行 `[].toString()`, 得到的结果是 `''`. `{}` 拆箱会先执行 `{}.valueOf()`, 得到的是 `{}`, 并不是原始值, 于是执行 `toString()`, 得到的结果是 `[object Object]`.
`[] + {}`就相当于`"" + "[object Object]"`, 结果就是`[object Object]`.`{} + []`的话, js 会把开头的`{}`理解成代码块, 这是因为有自动分号插入(ASI), 变成了`{}; + []`, 所以这句话就相当于`+[]`, 也就是等于`+""`, 将空字符串转换为数字类型, 结果就是 0.`{} + {}`的话, 也是和上面一样的道理, 相当于`+"[object Object]"`, 将字符串转化为数字类型, 结果是 NaN.`[] + []`就相当于`"" + ""`, 所以结果还是`""`.
下面是一段小的总结:
- 加号运算中, 不能确定左, 右操作数的类型
- 等值(
`==`)运算中, 不能确定左, 右操作数的类型, JavaScript 认为, 如果左, 右操作数之一为 string, number, bigint 和 symbol 四种基础类型之一, 而另一个操作数是对象类型(x), 那么就需要将对象类型转换成基础类型`ToPrimitive(x)`来进行比较. 操作数将尽量转换为数字来进行比较, 即最终结果将等效于: Number(x) == Number(y). `new Date(x)`中, 如果 x 是一个非`Date()`实例的对象, 那么将尝试把 x 转换为基础类型 x1; 如果 x1 是字符串, 尝试从字符串中 parser 出日期值; 否则尝试`x2 = Number(x1)`, 如果能得到有效的数字值, 则用 x2 来创建日期对象. 与上述拆箱相反, Date 的预设类型优先是 string, 因此会先调用 toString(), 再去调用 valueOf().

PREVIOUS POST
そのうちプラン
![[HTTP 系列] 第 4 篇 —— HTTPS](https://edge.yancey.app/beg/bwpaxvae-1649090731409.jpg)
NEXT POST
[HTTP 系列] 第 4 篇 —— HTTPS