
ChatGPT Prompt Engineering for Developers
4 月 27 日, Ng 和 OpenAI 团队共同出品了 9 节 ChatGPT Prompt Engineering for Developers 课程. 作为 ChatGPT 的花式调教用户, 和不专业的 "Prompt Engineer", 趁着五一放假学习一下, 若有谬误共同探讨.
Introducing Large Language Models
大语言模型分为 Base LLM 和 Instruction Tuned LLM.
基础语言模型是指只在大规模文本语料中进行了预训练的模型, 未经过指令和下游任务微调, 以及人类反馈等任何对齐优化. 它主要用于预测下一个单词.
比如你的提示词是 "Once upon a time, there was a unicorn", 基础语言模型可能会给你返回 "that lived in a magical forest with all her unicorn friends".
再比如你的提示词是 "What is the capital of France?", 它可能会给你返回 "What is France's largest city? What is France's population? What is the currency of France?"
事实上, 我们仅仅想得到 "Paris", 但为什么会输出上面的结果呢? 因为基础语言模型的作用是预测并补全, 并非指令性的回答, 因此对于这个返回, 它可能学到的是一段关于法国知识小测验的列表.
而 Instruction(指令) 是指通过自然语言形式对任务进行描述, 它在基础语言模型的基础上进一步训练, 用输入和输入进一步微调, 这些输入和输出都是指令.
此外, 在微调时使用了从人类反馈中进行强化学习的方法(Reinforcement Learning from Human Feedback, RLHF), 这里的人类反馈其实就是人工标注数据来不断微调 LLM, 主要目的是让 LLM 学会理解人类的命令指令的含义, 使得在一般文本数据语料库上训练的语言模型能和复杂的人类价值观对齐.
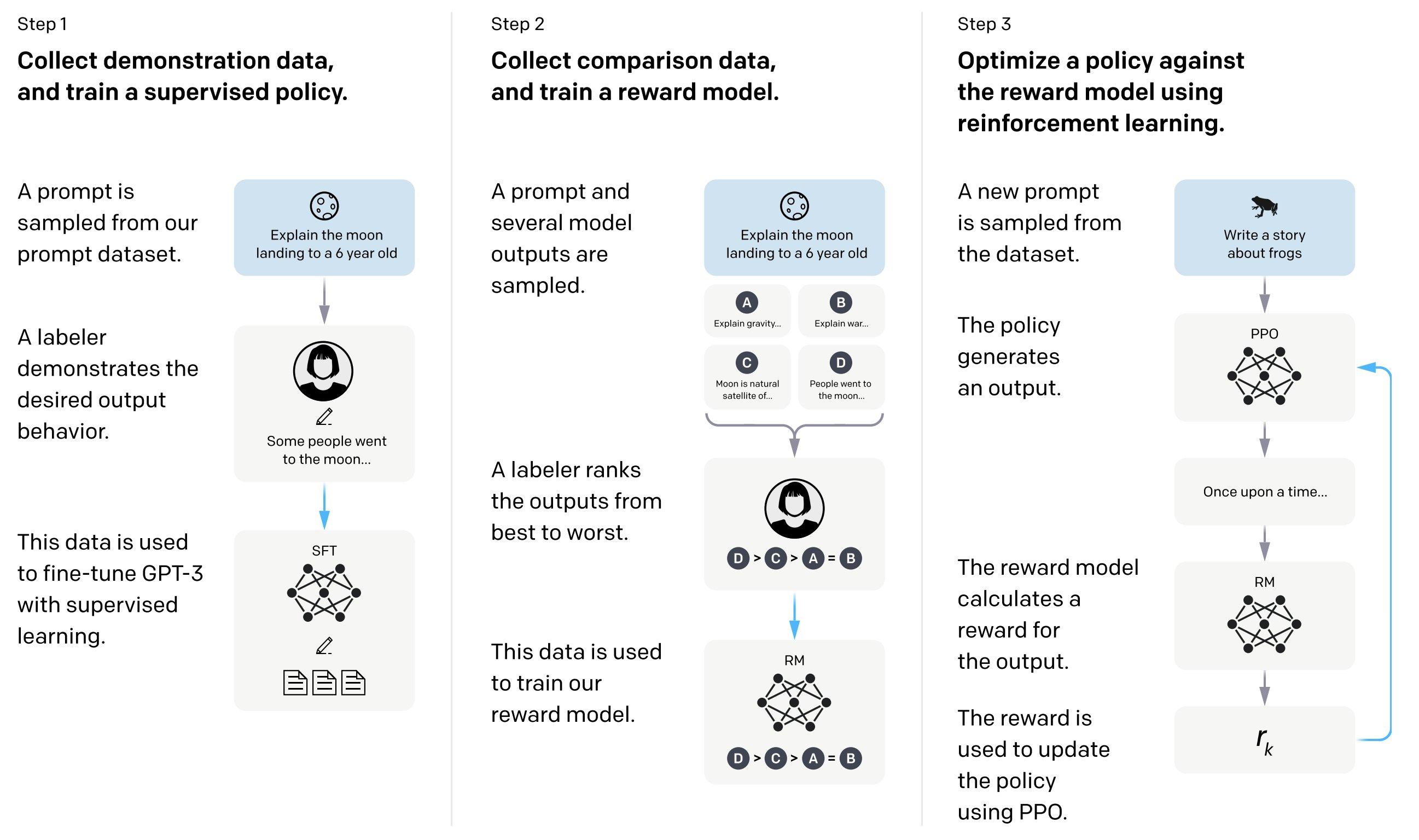
以 OenAI 的 GPT 为例, GPT-3 就是 Base LLM; GPT-3.5 就是 Instruction Tuned LLM; 而 ChatGPT 是在 GPT-3.5 基础上进行微调得到的, 用到了 RLHF 技术.
Two key principals for how to write prompts effectively
Write clear and specific instructions
首先要明确 clear 不意味着 short, 因为在很多情况下较长的提示能够提供更清晰地描述和上下文, 这也能够带来更加详细和确切的输出.
Tactic 1: Uses delimiters
分隔符来明确指出输入的不同部分
- Triple quotes:
`"""` - Triple backtick:
````` - Triple dashes:
`---` - Angle brackets:
`< >` - XML tags:
`<tag> </tag>`
举个例子, 下面是给星舰的介绍生成一句话摘要, 就可以将介绍文案包裹起来, 这里使用了 Triple backtick, 你也可以使用上述其他的分隔符. 总之这样就是告诉模型清楚的知道这是一个单独的部分.

再举个例子, 也是我在开发 rs_openai 是常干的事情, 就是让 ChatGPT 帮忙生成 Rust 结构体.
Generate the json string delimited by triple quotes into rust structs with serde and default. """ { "id": "chatcmpl-123", "object": "chat.completion", "created": 1677652288, "choices": [{ "index": 0, "message": { "role": "assistant", "content": "\n\nHello there, how may I assist you today?", }, "finish_reason": "stop" }], "usage": { "prompt_tokens": 9, "completion_tokens": 12, "total_tokens": 21 } } """
虽然当时也没用使用分隔符, ChatGPT 也足以给出优秀的答案. 不过既然看了这门课, 都听官方的. 🫡
#[derive(Debug, Deserialize, Default)] struct ChatCompletion { id: String, object: String, created: i64, choices: Vec<Choice>, usage: Usage, } #[derive(Debug, Deserialize, Default)] struct Choice { index: i32, message: Message, finish_reason: String, } #[derive(Debug, Deserialize, Default)] struct Message { role: String, content: String, } #[derive(Debug, Deserialize, Default)] struct Usage { prompt_tokens: i32, completion_tokens: i32, total_tokens: i32, }
此外, 视频介绍了要避免提示词注入, 它举了如下例子. 即开头提示模型来总结 ````` 之间的文字, 但黄色部分又要求模型不去做总结, 转而写一首关于 cuddy panda bears 的诗. 这种语意矛盾的 prompt 即为 prompt injections, 这是我们需要避免的.

Tactic 2: Ask for structured output
如下面的例子, 如果不提供输出结构, 它默认给出了一个 list 形式, 而如果你主动要求一个结构化的输出, 如 JSON, HTML 等等, 这样的好处是数据在你在代码中直接可用.

Tactic 3: Check whether conditions are satisfied
如果任务中的假设不一定被满足, 我们可以告诉模型先检查这些假设, 如果不满足, 我们指出这一点, 并在完成任务的过程中停止.
下面这个例子中, 如果指定文本是按步骤来的, 那就转换成 Step 的形式, 否则简单的返回 No steps provided.
第一个例子来阐述泡茶的步骤, 显然能够被转换成 Step 的形式. 并且我们看到它识别出了文本中的 If you like, 因此在 Step 5 标明了 Optional, 太牛逼了.
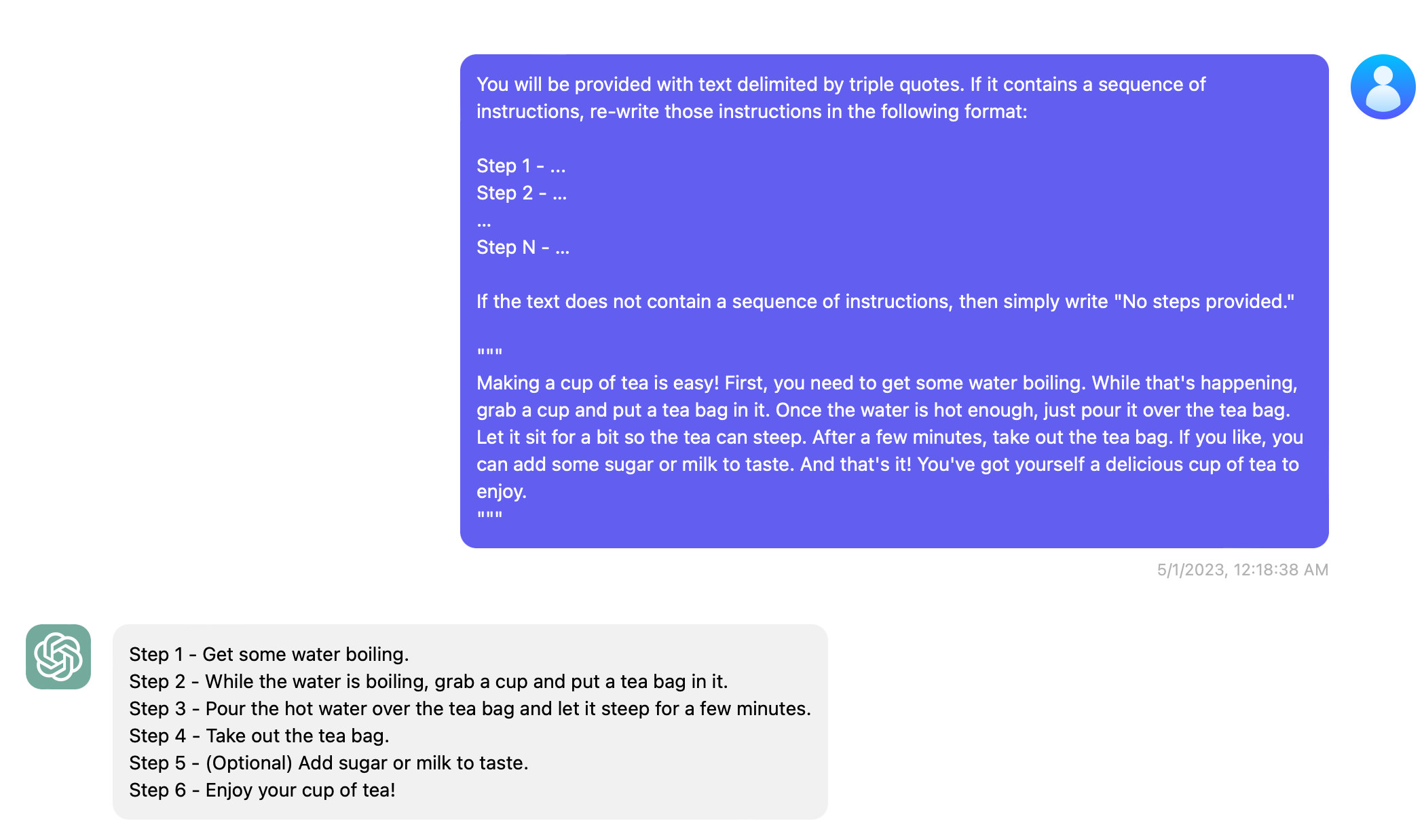
第二段话仅仅是描写天气和风景的文本, 不是步骤的形式, 那么模型直接识别 falsy 的部分, 简单返回 No steps provided. 即可.
Tactic 4: "Few-shot" prompting
这个策略的意思是: 在要求模型做你想让它做的实际任务之前, 给予模型一个明确的, 成功的例子, 让模型照着这个例子输出新的文本, 从而达到一致性.
下面这个例子, 我们想让模型输出 Answer: XXXX 这样一种格式, 并且语气要跟示例一中的 Answer 一致. 首先喂给模型一个例子, Question: 如何促进拉新, Answer 就是从网上抄的一段互联网黑话. 在输出中, 我们看到 ChatGPT 返回了我们想要的格式, 并且模仿了互联网黑化的语气解释了如何保证留存这一话题.

Give the model time to "think"
第二个原则给予模型更多的思考时间. 如果一个模型急于得出不正确的结论而出现推理错误, 你应该尝试重新设计询问, 以便在模型提供最终答案之前请求一系列相关推理.
Tactic 1: Specify the steps required to complete a task
具体来讲, 如果你的一个 prompt 需要完成多件事情, 最好的做法是用分步的形式来描述.
下面的例子依次是: 总结这段话; 把这段话翻译成日语; 把段落中提到的人名翻译成日语; 生成包含 japanese_summary 和 num_names 的 JSON 数据.
最后还要求每个答案之间用空行隔开, 这样能保证一个漂亮的输出效果.
Perform the following actions: 1 - Summarize the following text delimited by triple quotes with 1 sentence. 2 - Translate the summary into Japanese. 3 - List each name in the Japanese summary. 4 - Output a json object that contains the following keys: japanese_summary, num_names. Separate your answers with line breaks. Text: """ In a charming village, siblings Jack and Jill set out on a quest to fetch water from a hilltop well. As they climbed, singing joyfully, misfortune struck—Jack tripped on a stone and tumbled down the hill, with Jill following suit. Though slightly battered, the pair returned home to comforting embraces. Despite the mishap, their adventurous spirits remained undimmed, and they continued exploring with delight. """

但是上面这个例子有个缺点, 我们看到第三个 `List each name in the Japanese summary.` 这里, 它把 name 也翻译成了日语. 因此为了更加准确, 可以给它一个可预测的更加精确的输出形式.
下面是一个优化的例子:
Your task is to perform the following actions: 1 - Summarize the following text delimited by <> with 1 sentence. 2 - Translate the summary into Japanese. 3 - List each name in the Japanese summary. 4 - Output a json object that contains the following keys: japanese_summary, num_names. Use the following format: Text: <text to summarize> Summary: <summary> Translation: <summary translation> Names: <list of names in Japanese summary> Output JSON: <json with summary and num_names> Text: < In a charming village, siblings Jack and Jill set out on a quest to fetch water from a hilltop well. As they climbed, singing joyfully, misfortune struck—Jack tripped on a stone and tumbled down the hill, with Jill following suit. Though slightly battered, the pair returned home to comforting embraces. Despite the mishap, their adventurous spirits remained undimmed, and they continued exploring with delight. >

Tactic 2: Instruct the model to work out its own solution before rushing to a conclusion
这条策略的意思是: 不要让模型基于对某件事下结论, 而是在得出结论前, 先得出自己的结论.
下面这个例子是出了一道题目, 并让模型判断判断学生的答案是否正确. 下面的答案显然是错的, 因为是 `and an additional $10 / square foot`, 而学生的答案写成了 100. 但很遗憾的是, 模型给出的回复是 `The student's solution is correct.`.
Determine if the student's solution is correct or not. Question: I'm building a solar power installation and I need help working out the financials. - Land costs $100 / square foot - I can buy solar panels for $250 / square foot - I negotiated a contract for maintenance that will cost me a flat $100k per year, and an additional $10 / square foot What is the total cost for the first year of operations as a function of the number of square feet. Student's Solution: Let x be the size of the installation in square feet. Costs: 1. Land cost: 100x 2. Solar panel cost: 250x 3. Maintenance cost: 100,000 + 100x Total cost: 100x + 250x + 100,000 + 100x = 450x + 100,000

为什么模型认为是对的呢? 因为你给模型的要求是判断学生的答案是否正确, 因此模型更关心学生的解决方案而非问题, 即下面这段 Prompt:
Let x be the size of the installation in square feet. Costs: 1. Land cost: 100x 2. Solar panel cost: 250x 3. Maintenance cost: 100,000 + 100x Total cost: 100x + 250x + 100,000 + 100x = 450x + 100,000
这样一条一条读下来, 从逻辑上确实能从 1 2 3 得到 Total cost, 因此模型认为是正确的.
我们改一下这个例子, 开头要求在让模型先自己解决这个问题, 然后再去判断学生的答案是否正确, 并且强调了在模型未解决这个问题之前, 不允许判断学生的答案是否正确.
Your task is to determine if the student's solution is correct or not. To solve the problem do the following: - First, work out your own solution to the problem. - Then compare your solution to the student's solution and evaluate if the student's solution is correct or not. Don't decide if the student's solution is correct until you have done the problem yourself. Use the following format: Question: """ question here """ Student's solution: """ student's solution here """ Actual solution: """ steps to work out the solution and your solution here """ Is the student's solution the same as actual solution just calculated: """ yes or no """ Student grade: """ correct or incorrect """ Question: """ I'm building a solar power installation and I need help working out the financials. - Land costs $100 / square foot - I can buy solar panels for $250 / square foot - I negotiated a contract for maintenance that will cost me a flat $100k per year, and an additional $10 / square foot What is the total cost for the first year of operations as a function of the number of square feet. """ Student's solution: """ Let x be the size of the installation in square feet. Costs: 1. Land cost: 100x 2. Solar panel cost: 250x 3. Maintenance cost: 100,000 + 100x Total cost: 100x + 250x + 100,000 + 100x = 450x + 100,000 """ Actual solution:

Model Limitations
尽管语言模型在训练过程中已经接触了大量的知识, 但在其训练过程中, 它并没有完美的记住它所看到的信息, 因此它对一些知识边界并不了解, 这意味着它可能回答一些晦涩难懂的问题, 并且可以编造一些听起来有道理但实际上并不真实的事情. 我们把这些由模型编造的想法称之为幻觉(Hallucination).
比如下面这个例子, 我捏造了 BMW 旗下有一款叫做库里南的跑车, 它仍能够一本正经的胡说八道, 因此尽量保证模型不一本正经的胡说八道之前, 先保证你的 Prompt 不一本正经的胡说八道.

Iterative Prompt Develelopment
没有人能够保证第一次写的 Prompt 就可以得到的想要的结果, 一如没人能保证一次算法模型训练就能达到想要的效果. Prompts 的设计亦如此, 如果第一次没达到效果, 那就在此基础上迭代优化, 总会得到想要的效果.
让我们举一个例子来描述如何反复迭代一个 Prompt, 让它最终能为我们使用. 下面这个例子提供了了一个椅子的说明书, 我们想让模型依据技术规格为之写一个营销文案.
Your task is to help a marketing team create a description for a retail website of a product based on a technical fact sheet. Write a product description based on the information provided in the technical specifications delimited by triple quotes. Technical specifications: """ OVERVIEW - Part of a beautiful family of mid-century inspired office furniture, including filing cabinets, desks, bookcases, meeting tables, and more. - Several options of shell color and base finishes. - Available with plastic back and front upholstery (SWC-100) or full upholstery (SWC-110) in 10 fabric and 6 leather options. - Base finish options are: stainless steel, matte black, gloss white, or chrome. - Chair is available with or without armrests. - Suitable for home or business settings. - Qualified for contract use. CONSTRUCTION - 5-wheel plastic coated aluminum base. - Pneumatic chair adjust for easy raise/lower action. DIMENSIONS - WIDTH 53 CM | 20.87” - DEPTH 51 CM | 20.08” - HEIGHT 80 CM | 31.50” - SEAT HEIGHT 44 CM | 17.32” - SEAT DEPTH 41 CM | 16.14” OPTIONS - Soft or hard-floor caster options. - Two choices of seat foam densities: medium (1.8 lb/ft3) or high (2.8 lb/ft3) - Armless or 8 position PU armrests MATERIALS SHELL BASE GLIDER - Cast Aluminum with modified nylon PA6/PA66 coating. - Shell thickness: 10 mm. SEAT - HD36 foam COUNTRY OF ORIGIN - Italy """
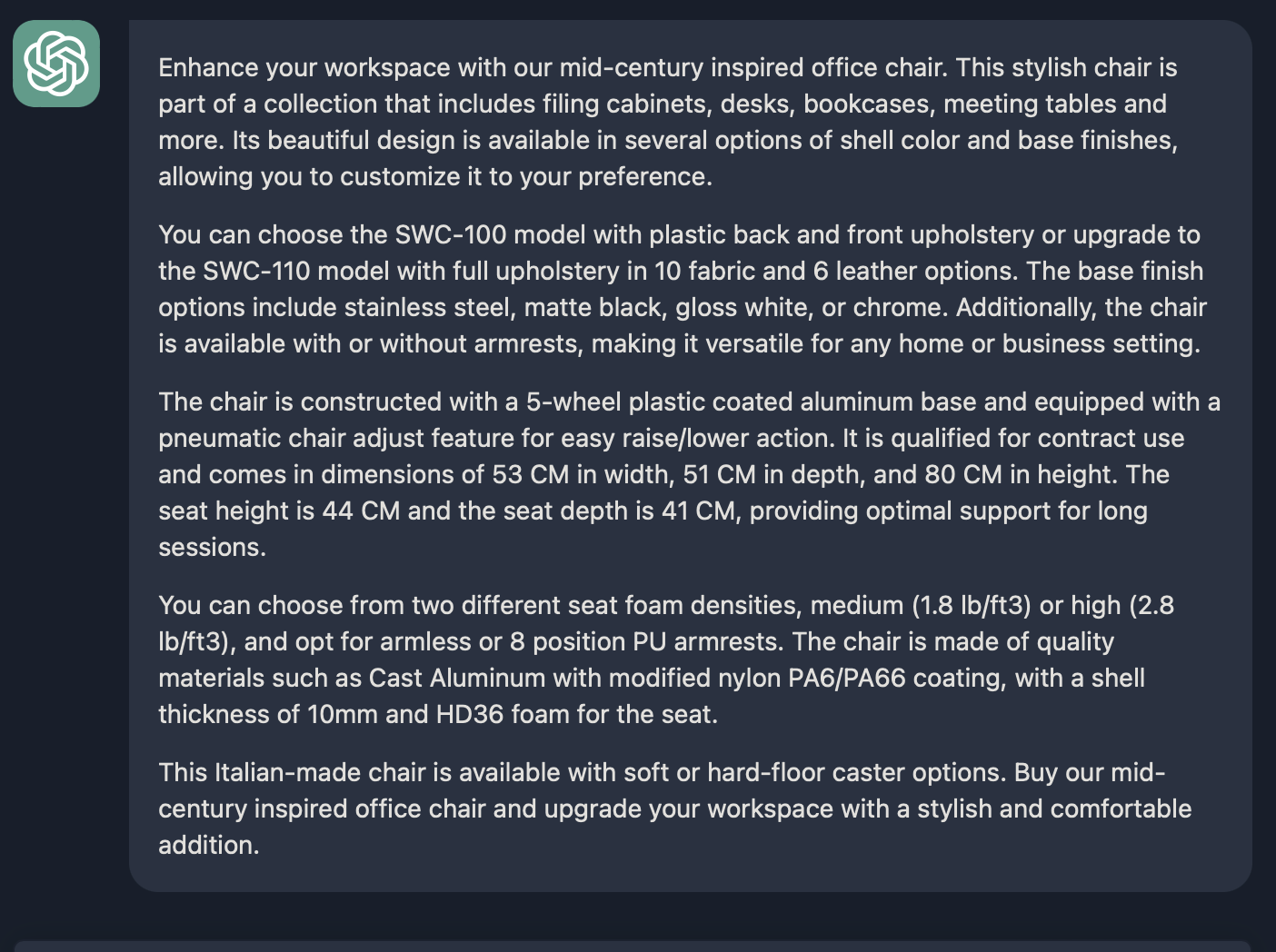
第一次迭代, 效果还不错, 按照技术规格书详细描述了这把椅子. 但问题是太长了. 我们尝试一次迭代, 在 Prompt 上加上一句 `Use at most 50 words.`, 再看一下效果, 发现还不错.
Your task is to help a marketing team create a description for a retail website of a product based on a technical fact sheet. Write a product description based on the information provided in the technical specifications delimited by triple quotes. Use at most 50 words. ...

但我们通过 `string.split(' ').length` 可以看出这段话足足有 67 个单词, 并没有满足我们设想的最多 50 个单词的要求. 这里需要知道的是, 大语言模型并不能很精确的按单词数量输出答案. 所以你可以换一些近似的修辞, 如 `Use at 3 sentences.` 或者 `Use at most 280 characters.` 多次尝试总会有一个接近你想要的效果.
让我们继续迭代, 假设我们的产品介绍语是面向家具零售商, 他们更关注技术参数以及材质.
Your task is to help a marketing team create a description for a retail website of a product based on a technical fact sheet. Write a product description based on the information provided in the technical specifications delimited by triple quotes. The description is intended for furniture retailers, so should be technical in nature and focus on the materials the product is constructed from. Use at most 50 words.

- 首先写一段给家具零售商的技术规格描述, 结尾标注上产品 ID
- 在描述后面写一个关于产品尺寸大小的 HTML 表格, 表格有两列, 第一列是尺寸名(如长, 宽, 高, 深度), 第二列是数值, 用英寸表示.
Your task is to help a marketing team create a description for a retail website of a product based on a technical fact sheet. Write a product description based on the information provided in the technical specifications delimited by triple quotes. The description is intended for furniture retailers, so should be technical in nature and focus on the materials the product is constructed from. At the end of the description, include every 7-character Product ID in the technical specification. After the description, include a table that gives the product's dimensions. The table should have two columns. In the first column include the name of the dimension. In the second column include the measurements in inches only. Give the table the title 'Product Dimensions'. Format everything as HTML that can be used in a website. Place the description in a <div> element. ...

最终的结果看起来还不错, 这启发我们要想达到一个完成一个不错的 Prompt, 是一个持续迭代的过程, 不可能一次性就能做到完美, 当效果不符合预期时, 可以尝试分析下哪些描述写的不好, 并试图基于模型一个更清晰的定义.
- Try something
- Analyze where the result does not give what you want
- Clarify instructions, give more time to think
- Refine prompts with a batch of examples
Summarize
文本总结是 nlp 领域的另一个亮点, 它能够把一个长文本精炼到几句话甚至一句话. 试想这么一个场景, 我们每天能够收到大量的用户调研信息, 如果能把这些调研信息加以总结和聚类, 是可以大幅降低产运分析成本.
比如我们有下面一段用户对宝马七系的评价, 要求生成一篇产品评论的简短摘要,摘要不超过 30 个单词。
型号: 宝马7系 2023款 735Li M运动套装 最满意: 这个宝马已经是我想了很久的款,为了买它还专门跑了省城。这个车动力确实很好,我提车开回来的时候在成都市区有点堵车,但是不管是方向灵动性还是加速超车性能,这个车都可以说是我开过的车里数一数一的。而且到现在为止,油耗也只有13个多,还是比较满意的,应该过了磨合期还要低一些。外观非常满意,从侧身看过去,车子程修长型,高调的修身感,让整个车子看上去都很高端大气。 最不满意: 比较不满意的点基本都是些小问题。例如新车提了车内还是有些味道的,首开的时候高速上我都是开了点窗户的。再一个就是遇到过两三次降速的过程中有顿挫感的时候。其他的就都是满意项。 空间: 这个车子内部不止前排位置元收,后排位置也一样不局限人,后排的扶手功能充实,方便实用,也让后面的位置一分为二,显得更大气。我身高体重偏中等,坐后面还有两拳宽的样子头部空间也预留得不错。后备箱放东西的能力也可以,至少正常家用或者商务足够。 驾驶感受: 3.0T发动机的加持之下,这C车的动力是很好的,特别是我我第一次开这个车回去的时候一上告诉油门一踩那个劲一下就上来了,反应之迅速。加上足够快的提速性,几乎是瞬间就能感受到推背感的强烈。但是这个车的隔音效果一般,特别是胎噪声比较大。然后在降速的时候遇到过顿挫感。档位这些的实体键做得很高端,使用起来舒适感也挺强。 油耗: 油耗我是满意的,一个五米多车长,还很重的车,在磨合期内能到13个油左右我是觉得挺不错了。 外观: 外观好看,时尚,科技感满满。看看车尾这个有棱有角的设计很霸气,颇有点大师风范。车头不必细说,家族式设计。 内饰: 用料很良心,这个要好评。颜色搭配很亮眼,特别是局部的木纹肌理感。中控台设计最好看,加上高档屏幕,非常亮眼。 性价比: 性价比还不错吧,这么价位没什么优惠力度,但是能接受。 配置: 倒车影像啊,车机系统啊,屏幕啊,隐形把手啊,都是高端配置的提现。
整体的摘要如下, 效果还是不错的.

当然你可以突出这篇摘要的目的, 比如生成一篇产品评论的简短摘要给发动机研发团队,摘要不超过 30 个单词, 它就会更强调跟动力油耗相关, 如: 宝马 7 系 2023 款 735Li M 运动套装,动力无可挑剔,油耗满意,外观高端大气,后排空间宽敞,配置高端。唯一不足是一些小问题。
再比如可以给用于定价团队, 它会更强调与价格相关的术语, 如: 这篇评论高度赞扬了宝马 7 系 2023 款的强劲引擎、燃油效率、宽敞的内部空间和高端的设计。评论者注意到了一些小问题,但总体认为这辆车的价值足以抵消其价格。
除了生成摘要, 还可以从指定的段落中提取信息, 比如提取这篇评论有关产品设计的信息, 它可能给你反馈如: 设计部门应该对外观和内饰设计感到满意,尤其是流畅而高端的外观,优质材料和引人注目的颜色组合。
Inferring
除了能够总结和提取, LLM 模型的另一大用途就是推断, 比如上面那段关于宝马七系产品的用户反馈, 模型可以推断用户对于这个产品整体感情是正向的还是负向的. 如:
请识别出如下产品反馈的用户情感, 该反馈使用三个反引号分隔. """ ... 型号: 宝马7系 2023款 735Li M运动套装 ... """ 最终给予的结果是满意, 是符合预期的.
当然很多时候, 我们绝不仅仅只分析一个用户的情感, 当我们需要分析一系列用户产品反馈时, 最好能让模型给予一个特定的输出, 比如:
除了能够总结和提取, LLM 模型的另一大用途就是推断, 比如上面那段关于宝马七系产品的用户反馈, 模型可以推断用户对于这个产品整体感情是正向的还是负向的. 如:
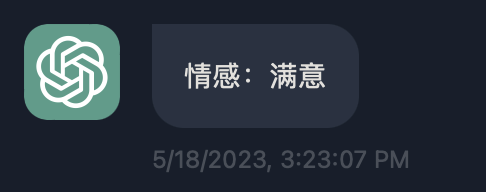
请识别出如下产品反馈的用户情感, 该反馈使用三个反引号分隔. """ ... 型号: 宝马7系 2023款 735Li M运动套装 ... """
最终给予的结果是满意, 是符合预期的.
当然很多时候, 我们绝不仅仅只分析一个用户的情感, 当我们需要分析一系列用户产品反馈时, 最好能让模型给予一个特定的输出, 比如:
请识别出如下产品反馈的用户情感, 该反馈使用三个反引号分隔. 如果用户满意输出 1, 否则输出 0. """ ... 型号: 宝马7系 2023款 735Li M运动套装 ... """
最终给予的结果是 1, 这样我们就很轻松的计算出这一批用户反馈中, 正向的占比是多少, 负向的占比又是多少.
上述做法中, 模型只是给予了一种非黑即白的反馈, 有时候你需要在这个用户反馈中推断出几个关键词, 可以像下面这样做:
找出如下用户产品反馈所表达的情绪列表, 不超过 5 项, 将答案用逗号分开, 该用户产品反馈使用三个反引号分隔. """ ... 型号: 宝马7系 2023款 735Li M运动套装 ... """
它给予了如下 5 个关键词, 整体效果是不错的.

此外, 你还可以预置一种情绪, 来让模型判断是否有这种情绪:
请识别出如下产品反馈的情感, 用户是否对该产品感到生气, 该反馈使用三个反引号分隔. """ ... 型号: 宝马7系 2023款 735Li M运动套装 ... """
它给予的反馈是情感积极, 没有生气的情绪, 这在客服系统是很有用的, 用于整体把控用户的情绪, 来派发不同的话术.

除了推断情绪, 还可以推断一段文本的主题(或者说关键词), 我们仍然用宝马七系这个例子:
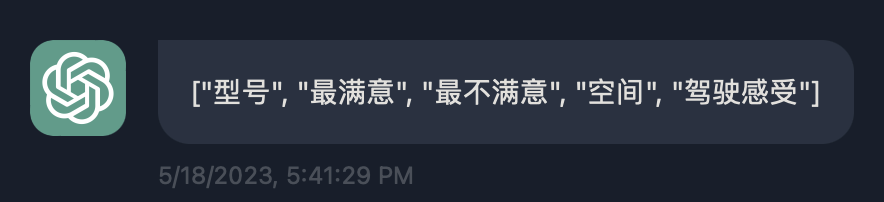
确定以下文本中正在讨论的五个主题, 每个主题不超过 10 个字, 并把主题词存储到一个 Rust Vec 中. 该文本由三个反引号分隔. """ ... 型号: 宝马7系 2023款 735Li M运动套装 ... """
Transforming
文本转换是另一个重要的功能, 常见的如文本翻译, 文本拼写/语法检查, 文本语调转换, 文本格式转换.
Translation
很多开发者开始通过 ChatGPT 来构建翻译应用, 我们看看如何写好一个翻译的 Prompt.
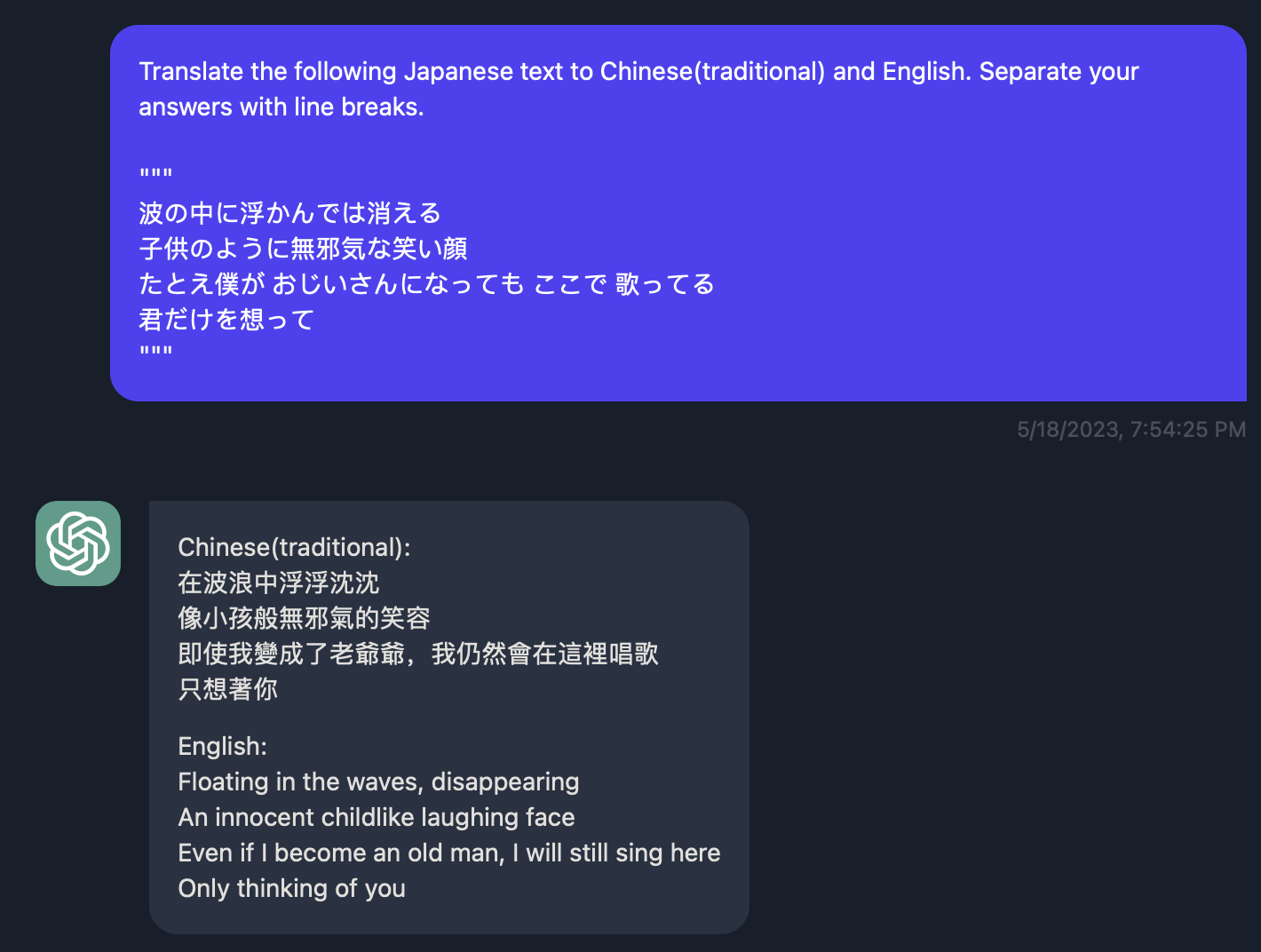
下面这个例子是把这段日语文本翻译成中文繁体和英语.
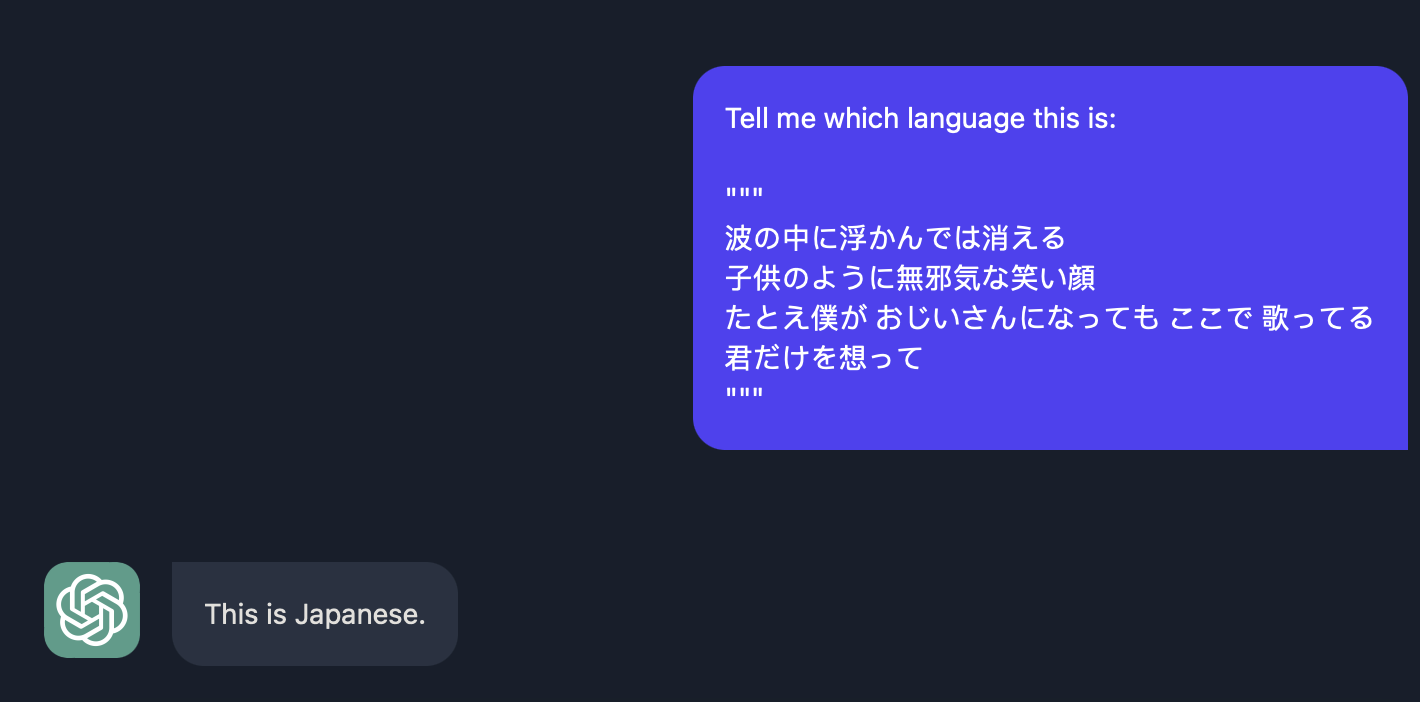
你也可以尝试询问它是什么语言.
Tone Transformation
它还可以进行文本语调转换, 比如调整语言的正式性和非正式性, 这块对于写邮件很有帮助.
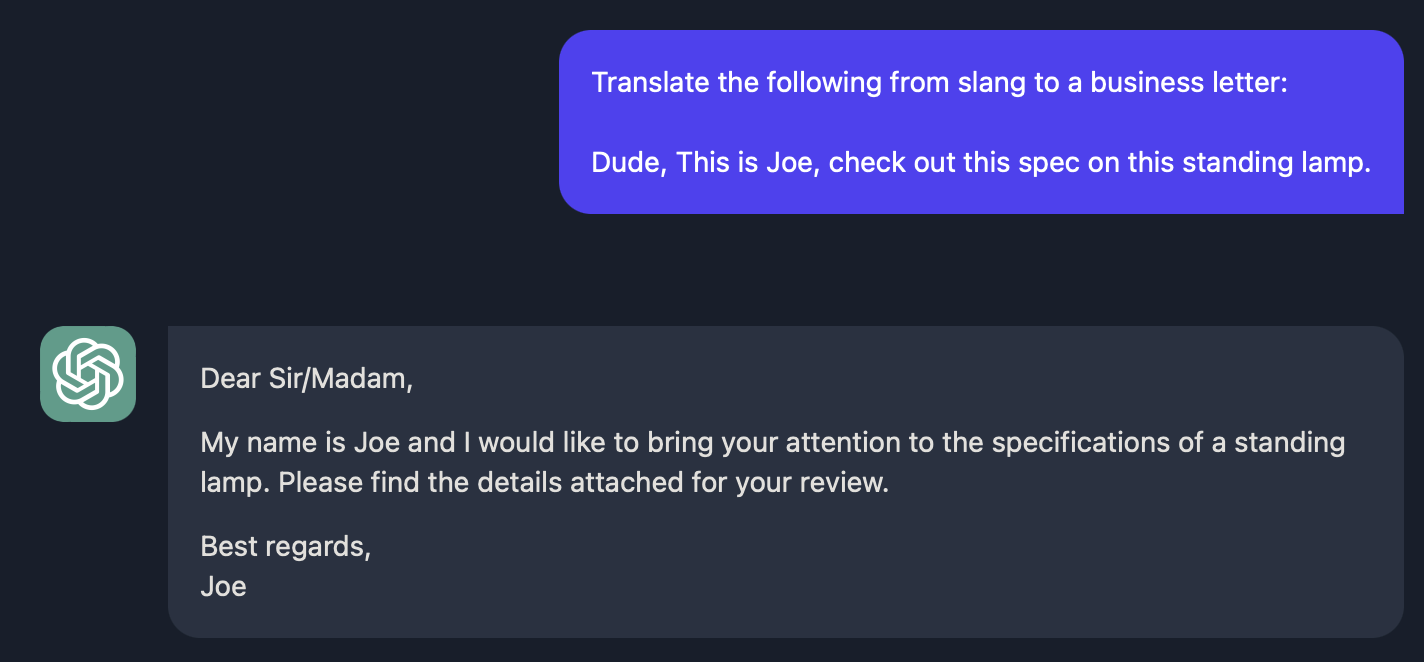
Format Conversion
我们在 Tactic 1: Uses delimiters 那里通过一段 JSON 字符串转换成 Rust structs, 这就是所谓的格式转换, 这里就不赘述了.
Spellcheck/Grammar check
最后我们在看一下拼写/语法检查, 从事实上来讲, ChatGPT 的出现, 直接把 Grammarly 这类平台干倒闭了, 让我们看看怎么写好一个拼写/语法检查的 Prompt.
很简单, 你可以直接告诉他将这段文本校正成正确的版本即可, 当然为了充分考虑边界情况, 在文本没有语法错误时, 输出 "No errros found".
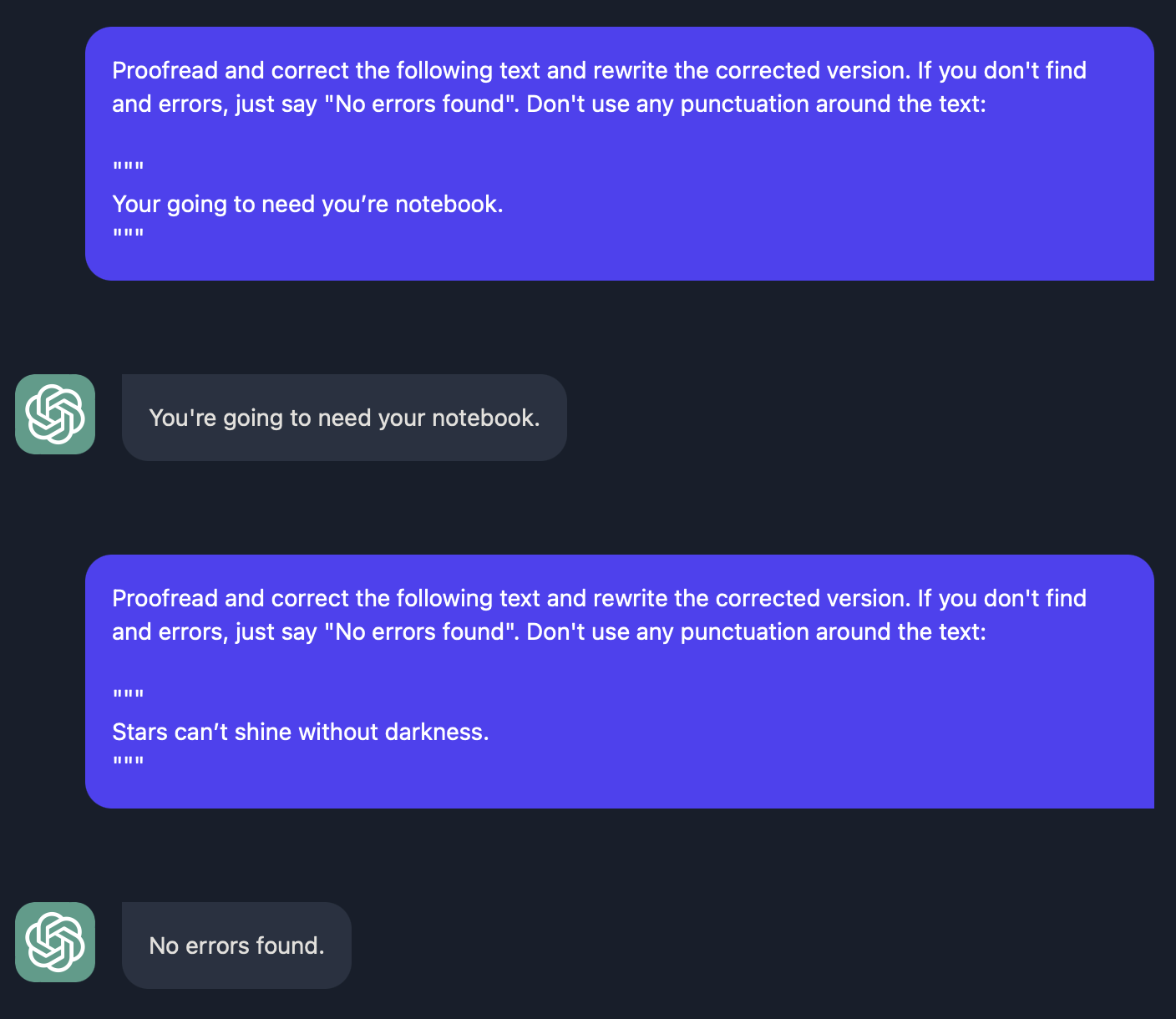
此外, 你可以做一些很酷的事情, 比如下面这段话, 让模型修正之后得到如下反馈.
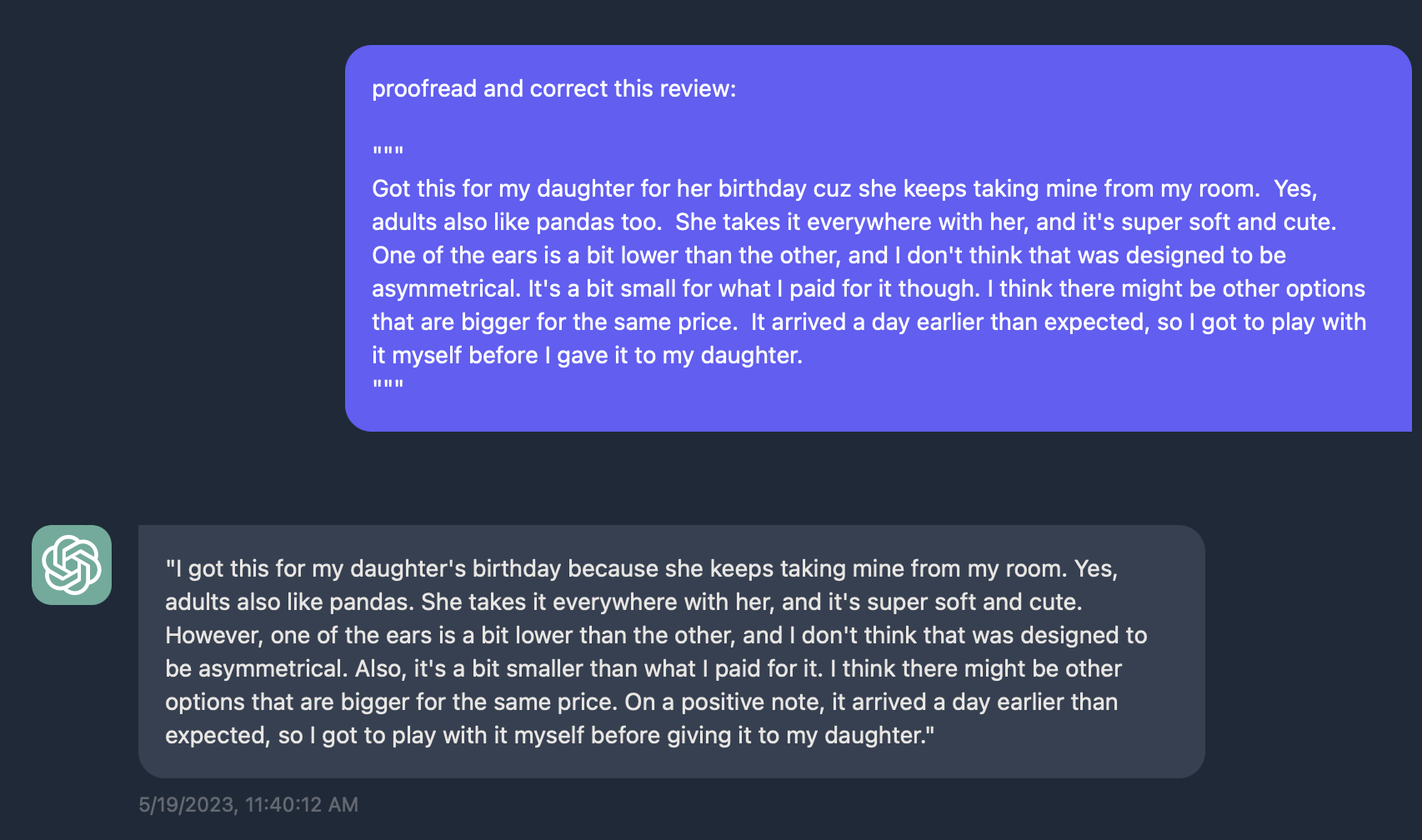
你可以通过一些三方库, 比如 redlines, 就可以得到如下效果:

Expanding
文本扩写是将一较短的文本进行扩写, 如一套指示或者主题列表, 并让大语言模型生成一段较长的文本, 比如一封文件或者一篇关于某个主题的文章, 也可能根据几个关键词, 让模型帮忙头脑风暴.
下面这个例子, 我们让模型扮演客服 AI 助理, 使用简洁且专业的语调回复用户的反馈邮件, 邮件开头要表达对用户反馈的 感谢. 然后分析用户这篇反馈的情绪是正向的还是负向的:
- 如果是正向的, 表达感谢并正常扩写邮件, 来对他们的评论进行感谢
- 如果是负向的, 表达抱歉并引导客户联系客服
最终的署名是 AI customer agent
You are a customer service AI assistant. Your task is to send an email reply to a valued customer. Given the customer email delimited by """, Generate a reply to thank the customer for their review. Firstly, inffer the sentiment of the email. If the sentiment is positive or neutral, thank them for their review. If the sentiment is negative, apologize and suggest that they can reach out to customer service. Make sure to use specific details from the review. Write in a and professional tone. Sign the email as `AI customer agent`. Customer review: ...
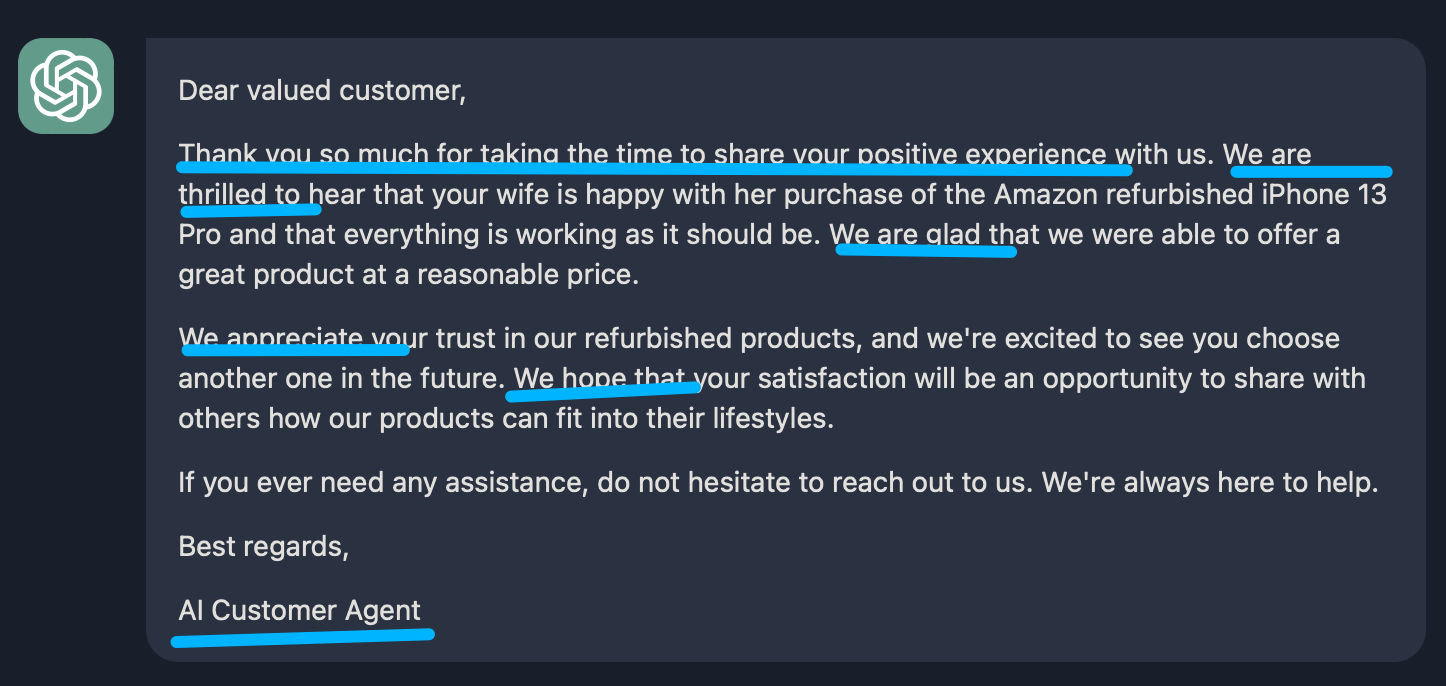
首先我们挑选一个正向的反馈:
Worth the money!!! This phone was purchased for my wife after I had purchase an iPhone 13 Pro, 256GB, from the Apple Store. My wife was not sure about purchasing a refurb phone but this was from Amazon so she gave it a try. She has been very happy with the purchase. Her friends were surprised with the phone being in such nice shape and were amazed my wife got double the memory for less money than their IPhone Purchase price from different carriers. The battery is fine. There are no scratches. Everything works as it did on my Apple Store phone. This is unlocked and all we had to do is insert the SIM from my wife’s old android phone to go live and use the IPhone. We did go down to our carrier’s store and get an updated, current SIM when it was convenient. When I upgrade I think I will go with an Amazon refurbished IPhone next time which can cost less money. My wife is happy!! What more can I say?
下面是最终的邮件效果, 整体看起来是很不错的.
然后我们在来一个相对负向的反馈:
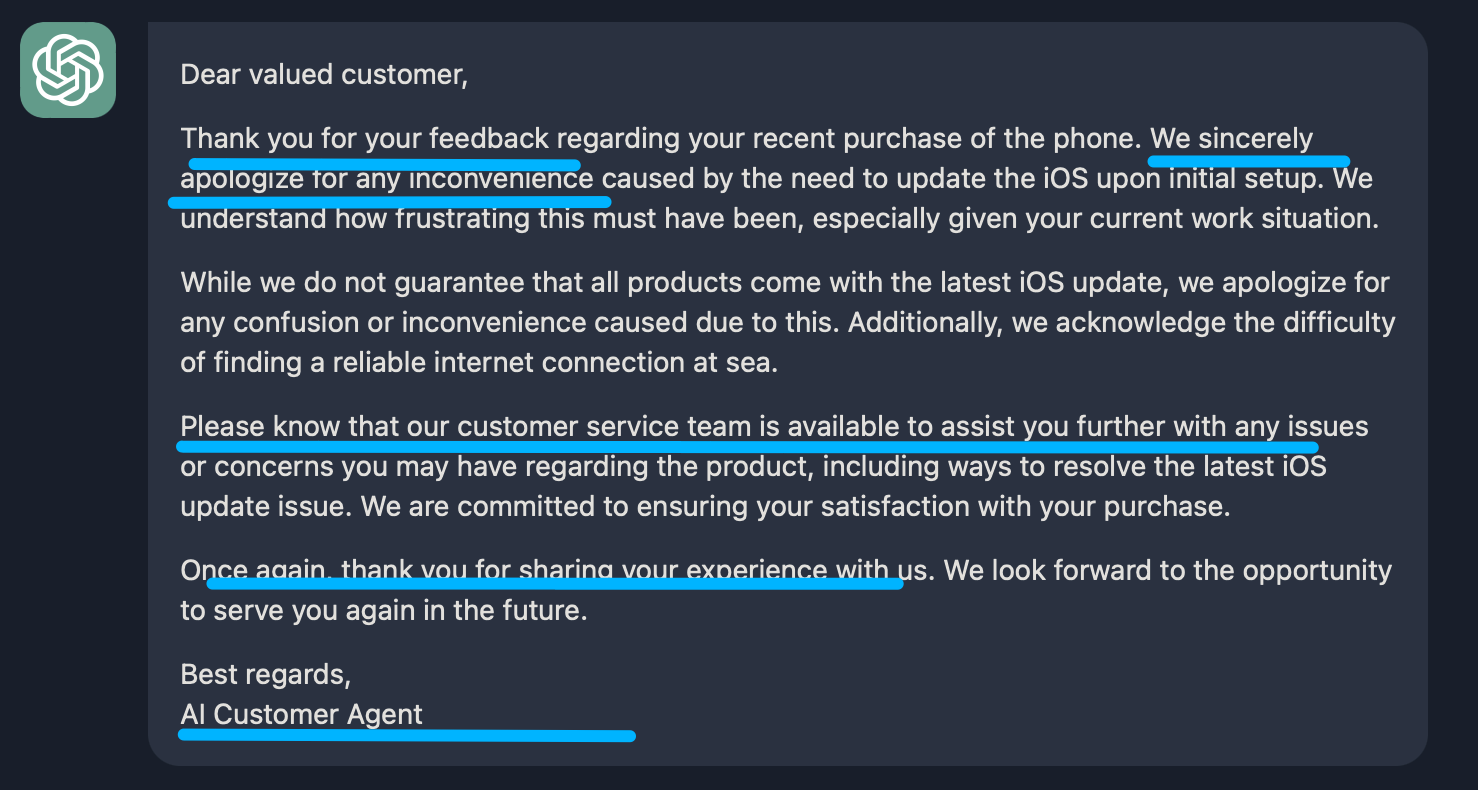
I got this phone but when I try set it up, it’s making me do the latest iOS update. Since this is an unlocked phone, I assumed it would have came with the latest update. I cannot get strong enough internet to update it as I work at sea on a cruise ship and all the stops we go to, I get off for a few hours for wifi and still it won’t install the update. I am extremely disappointed by this as i was so excited for the phone, now I have nothing.
基本上也是符合预期的, 首先表达歉意, 然后引导联系客服.
Temperature
我们知道 OpenAI 为我们提供了诸多 API, 其中创建聊天也是如此: Create chat completion. 我们常用的参数最主要就 prompt, 这里我们介绍另外一 个参数: Temperature.
这个参数的取值在 0 - 2 之间, 默认是 1, 如果取较高的值将使输出更加随机, 而较低的值将使输出更加集中和确定. 下面给出了一个事例, 假设你输入 my facorite food is, 它预测的下一个词可能是 pizza, sushi, tacos, 其中 pizza 比例为 53%, sushi 次之, tacos 更少.
如果你使用 `Temperature = 0`, 在多次请求后, 它都会给你输出 pizza, 因为这是最可预测的.
随着 Temperature 变大, 每次拿到的数据就会越随机, 可以看下面这张图.
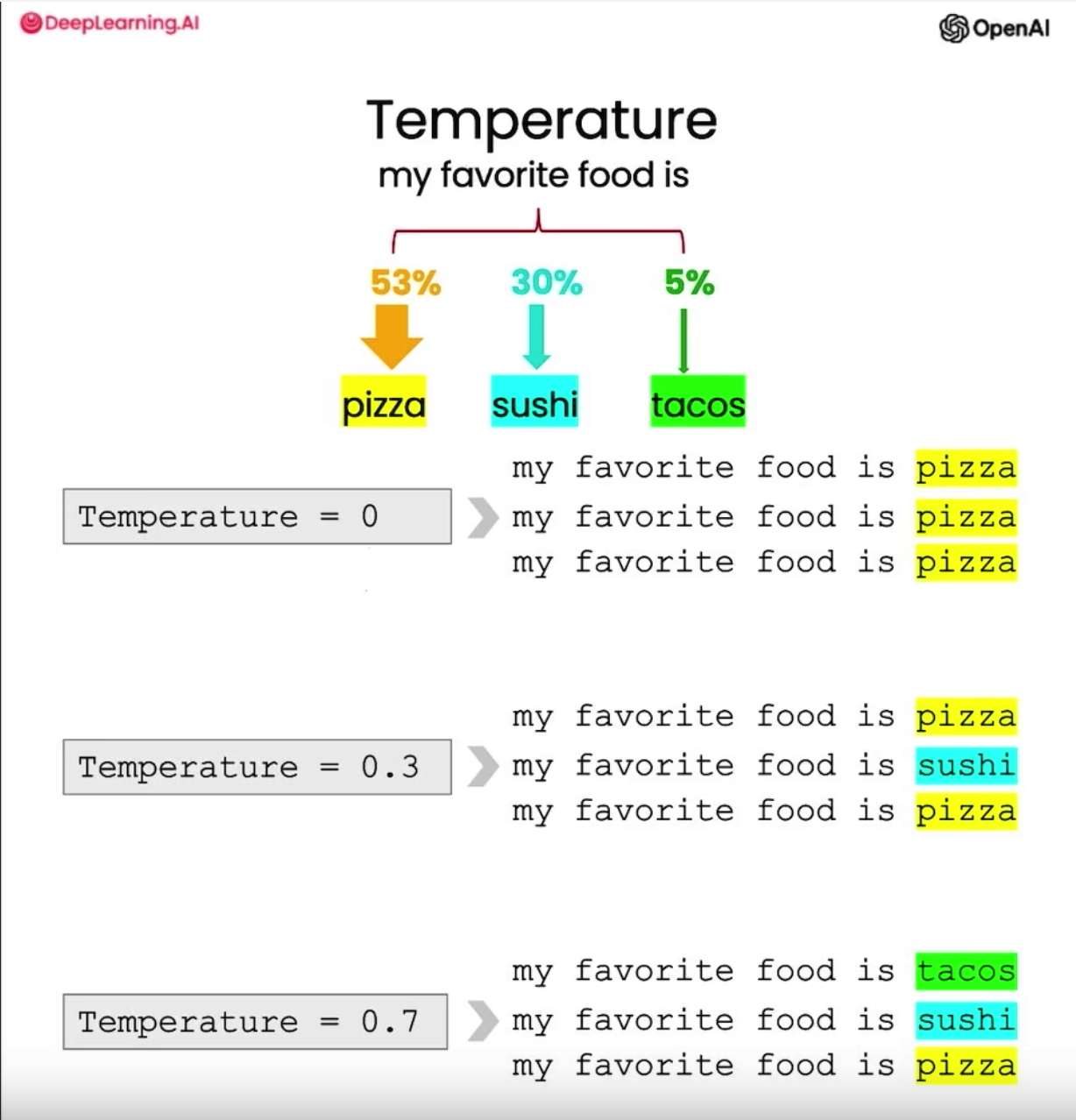
因此, 如果你想构建一个稳定, 可预测的系统, 比如上述邮件助理系统, 我们肯定希望从格式, 内容上更加一致, 那就把 Temperature 调小; 如果你希望模型能提供更多有创意的东西, 就可以将它调的大一些, 当然从人类的角度来讲, 此时的模型会变的不稳定且容易分心.
ChatBot
最后, 也是我们最感兴趣的 ChatBot, 我们从 System 和 Context 两个角度来阐述如何构建高效的聊天机器人.
System
ChatGPT 的 API 中 messages 参数接受一个数组, 它支持传入多个消息, 如:
messages = [ {'role':'system', 'content':'You are friendly chatbot.'}, {'role':'user', 'content':'Hi, my name is Isa'} ]
其中 `role` 参数支持 `system`, `user`, or `assistant` 三种枚举, 一般我们的角色就是 user, 但在一些特定的场景, 提前预置 `system` 可以给整个聊天定一个基调, 比如 `You are an assistant that speaks like Shakespeare.`, 那它后续就会以莎士比亚的口吻来回答, 这在一些特定客服环境很有用.
Context
我们在使用 ChatGPT 网页端的时候会发现他有记忆功能, 也就是说你在某个回话中已经交流过的内容, 会作为新的会话的参考. 比如我们询问模型一个问题, 我对它回答的结果不满意, 它会基于上面已给出的答案进行优化和修改. 这个技术便叫做 Context.
比如我有如下 prompt, 在没有上下文的情况下, 显然模型不知道我的名字, 于是它给出了 I'm sorry, but as a chatbot, I don't have access to your name unless you tell me what it is. 这样的回答.
messages = [ {'role':'system', 'content':'You are friendly chatbot.'}, {'role':'user', 'content':'Yes, can you remind me, What is my name?'} ]
但如果我们给出足够的上下文, 如下这个例子, 模型就能知道你的名字: Of course! Your name is Isa. It's a pleasure to assist you, Isa.
messages = [ {'role':'system', 'content':'You are friendly chatbot.'}, {'role':'user', 'content':'Hi, my name is Isa'}, {'role':'assistant', 'content': "Hi Isa! It's nice to meet you. Is there anything I can help you with today?"}, {'role':'user', 'content':'Yes, you can remind me, What is my name?'} ]
因此, 我们在设计 ChatBot 时, 也可以在每次提交时, 带上前几个会话的上下文信息. 不过由于有 token 数量限制, 你带的历史上下文信息多了, 可能就会报错, 因此需要具体问题具体分析, 比如带上最新三个到五个历史回会话. 抑或通过 langchain 这样的库进行精细化分割.
Example
下面举一个例子, 比如让 Bot 扮演一个卖披萨的机器人:
- 首先问侯客户, 然后收集订单, 接下来询问客户堂食还是外卖.
- 等到收集完订单后对订单做一个总结, 并询问客户是否需要其他的.
- 如果客户选择外卖, 询问客户地址信息.
- 最后计算金额.
[ {'role':'system', 'content':""" You are OrderBot, an automated service to collect orders for a pizza restaurant. \ You first greet the customer, then collects the order, \ and then asks if it's a pickup or delivery. \ You wait to collect the entire order, then summarize it and check for a final \ time if the customer wants to add anything else. \ If it's a delivery, you ask for an address. \ Finally you collect the payment.\ Make sure to clarify all options, extras and sizes to uniquely \ identify the item from the menu.\ You respond in a short, very conversational friendly style. \ The menu includes \ pepperoni pizza 12.95, 10.00, 7.00 \ cheese pizza 10.95, 9.25, 6.50 \ eggplant pizza 11.95, 9.75, 6.75 \ fries 4.50, 3.50 \ greek salad 7.25 \ Toppings: \ extra cheese 2.00, \ mushrooms 1.50 \ sausage 3.00 \ canadian bacon 3.50 \ AI sauce 1.50 \ peppers 1.00 \ Drinks: \ coke 3.00, 2.00, 1.00 \ sprite 3.00, 2.00, 1.00 \ bottled water 5.00 \ """} ]
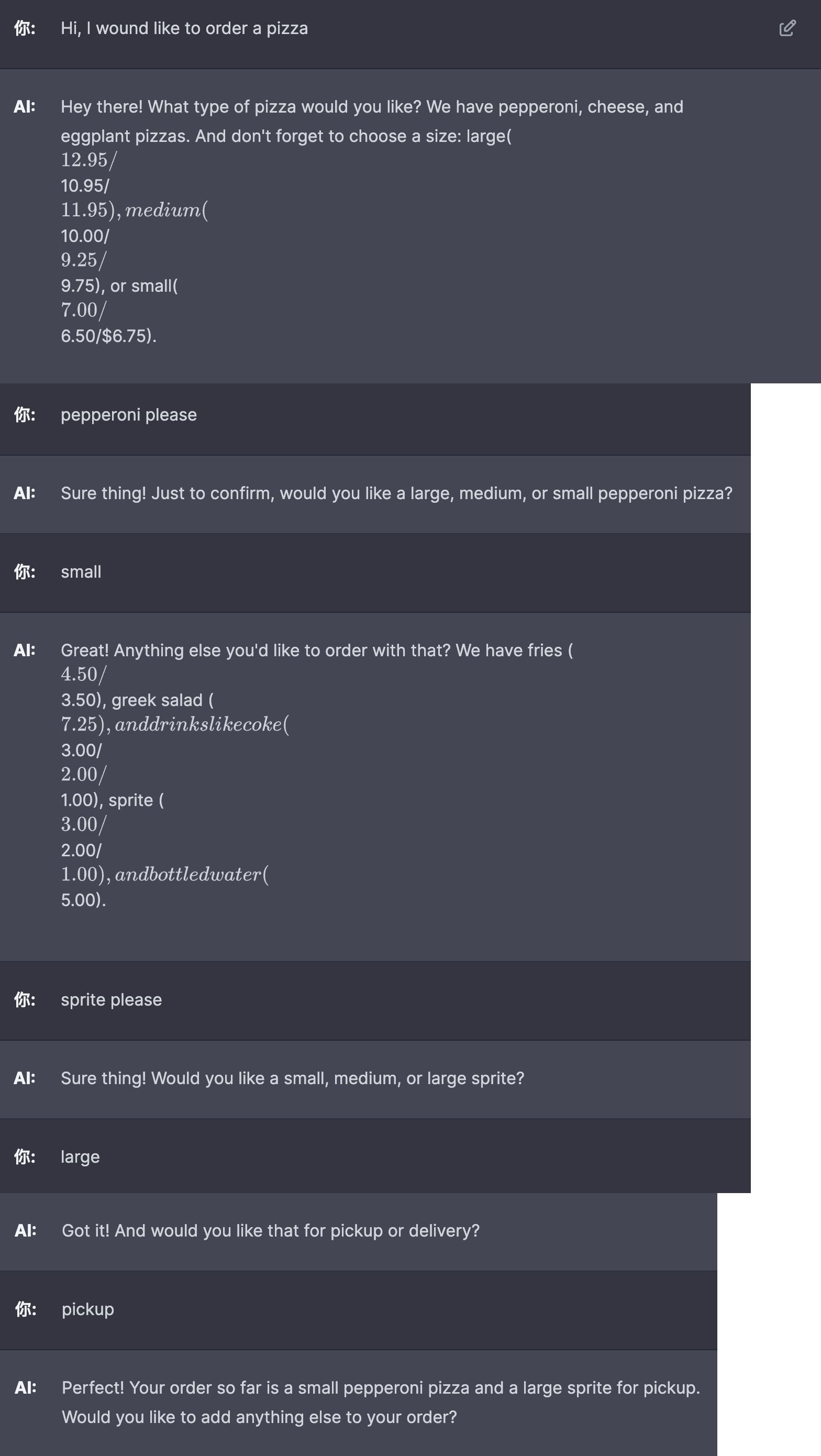
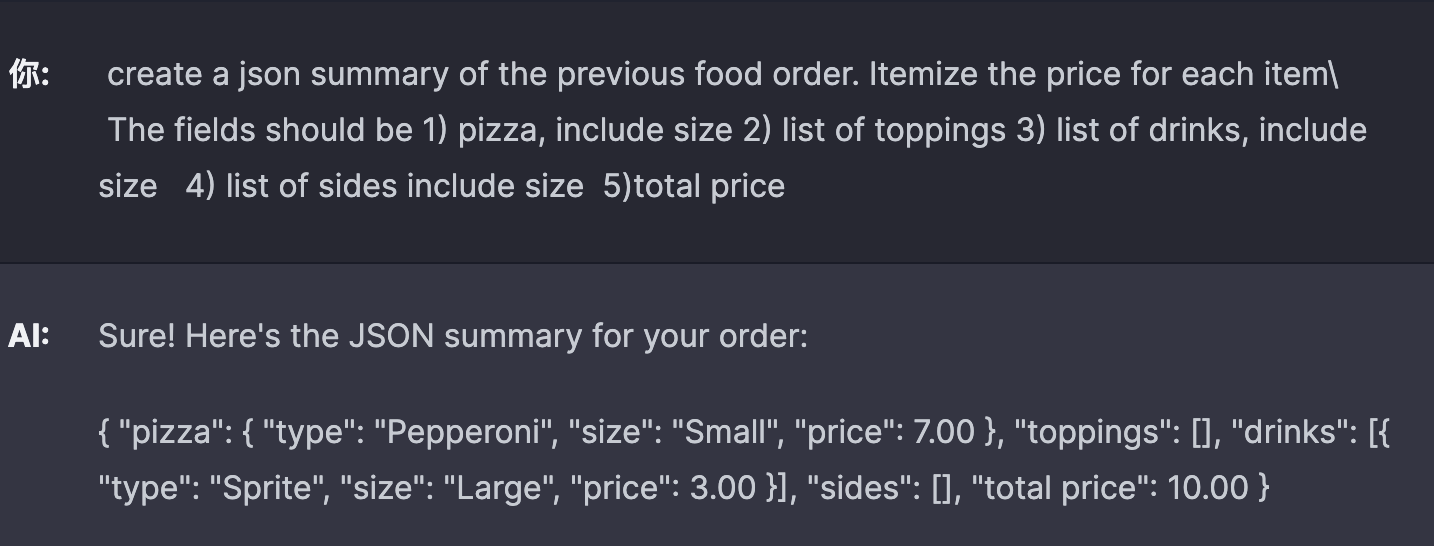
当然更进一步, 你可以将上面的订单结果生成 JSON 代码, 那就完全可以替代人类完成询问 - 下单 - 入库等一系列流程了. 当然为了让输出更加可预测, 我们可以选择将 temperature 设置得足够小.
Conclusion
在这门课中, 我们学到了 prompt 的两个基准原则:
- Write clear and specific instructions
- Give the model time to "think"
接着我们学到了 Iterative Prompt Develelopment, 即没有人能一次就写出完美的 prompt, 二十需要通过不断迭代和优化, 使结果更好的为我们利用.
此外, 我们学到了 LLM 模型的一些能力, 如总结, 推断, 转换, 扩写.
最后我们学到了如何通过 system 和 context 两大原则建立一个定制化的订单机器人.
Appendix: Implement stream in JavaScript
最后作为附录, 奉上如何使用 ChatGPT 的 stream 模式构建你的用户交互.
import { FC, useState } from 'react' import classNames from 'classnames' import ReactMarkdown from 'react-markdown' import { Prism as SyntaxHighlighter } from 'react-syntax-highlighter' import { oneDark as mdCodeTheme } from 'react-syntax-highlighter/dist/esm/styles/prism' import rehypeMathjax from 'rehype-mathjax' import remarkGfm from 'remark-gfm' import remarkMath from 'remark-math' import Card from '@mui/material/Card' import CardContent from '@mui/material/CardContent' import Button from '@mui/material/Button' import Input from '@mui/material/Input' export interface OpenAIChatDelta { role?: string content?: string } export interface OpenAIChatChoice { delta: OpenAIChatDelta index: number finish_reason: string | null } export interface OpenAIChatResponse { id: string object: string created: number model: string choices: OpenAIChatChoice[] } const ChatGPT: FC = () => { const [prompt, setPrompt] = useState('') const [anwser, setAnwser] = useState<string>('') const resolveData = async ( reader: ReadableStreamDefaultReader<Uint8Array> ): Promise<void> => { const { done, value } = await reader.read() if (done) { return reader.releaseLock() } const decoder = new TextDecoder('utf-8') const chunk = decoder.decode(value, { stream: true }) const chunks: OpenAIChatResponse[] = chunk .split('data:') .map((data) => { const trimData = data.trim() if (trimData === '') return undefined if (trimData === '[DONE]') return undefined return JSON.parse(data.trim()) }) .filter((data) => data) chunks.forEach((data) => { const token = data.choices[0].delta.content if (token !== undefined) { setAnwser((prevState) => prevState + token) } }) return resolveData(reader) } const resolveError = async ( reader: ReadableStreamDefaultReader<Uint8Array> ) => { const { value } = await reader.read() const decoder = new TextDecoder('utf-8') const chunk = decoder.decode(value, { stream: true }) const errorData = JSON.parse(chunk) console.log(errorData) return } const createChatCompletion = async () => { const chat = await fetch('https://api.openai.com/v1/chat/completions', { headers: { 'Content-Type': 'application/json', Authorization: `Bearer ${import.meta.env.VITE_OPENAI_SECRET_KEY}` }, method: 'POST', body: JSON.stringify({ messages: [ { role: 'user', content: prompt } ], model: 'gpt-3.5-turbo', stream: true }) }) const reader = chat.body?.getReader() if (!reader) return if (chat.status !== 200) { resolveError(reader) } await resolveData(reader) reader.releaseLock() } return ( <section> <section className="flex"> <Input value={prompt} onChange={(e) => setPrompt(e.target.value)} sx={{ width: 400, marginRight: 2 }} /> <Button variant="contained" onClick={createChatCompletion} disabled={!prompt.trim()} > Search </Button> </section> {anwser && ( <Card sx={{ maxWidth: 800, marginTop: 2, marginBottom: 2 }}> <CardContent> <ReactMarkdown remarkPlugins={[remarkGfm, remarkMath]} rehypePlugins={[rehypeMathjax]} components={{ code({ inline, className, children }) { const match = /language-(\w+)/.exec(className || '') return !inline ? ( <SyntaxHighlighter style={mdCodeTheme} language={match ? match[1] : ''} PreTag="div" customStyle={{ borderRadius: 0, margin: 0 }} > {String(children).replace(/\n$/, '')} </SyntaxHighlighter> ) : ( <code className={classNames('font-semibold', className)}> `{children}` </code> ) }, p({ className, children }) { return ( <p className={classNames(className, 'mb-4')}>{children}</p> ) }, pre({ className, children }) { return ( <pre className={classNames(className, 'mb-4 text-sm')}> {children} </pre> ) }, ol({ className, children }) { return ( <ol className={classNames(className, 'mb-4 pl-4 list-disc')} > {children} </ol> ) }, ul({ className, children }) { return ( <ul className={classNames( className, 'mb-4 pl-4 list-decimal' )} > {children} </ul> ) }, li({ className, children }) { return ( <li className={classNames(className, 'mb-4')}> {children} </li> ) } }} > {anwser} </ReactMarkdown> </CardContent> </Card> )} </section> ) } export default ChatGPT

PREVIOUS POST
浅析 V8 原理

NEXT POST
教你在中国大陆足不出户开通境外汇丰银行卡